前端常见面试题合集

前端常见面试题合集
dleeivue
对vue的理解
Vue.js(/vjuː/,或简称为Vue)是一个用于创建用户界面的开源JavaScript框架,也是一个创建单页应用的Web应用框架。Vue所关注的核心是MVC模式中的视图层,由数据驱动视图,把重点放在操作数据上
1.vue的核心特征就是主要有三点
数据驱动,所谓的数据驱动就是 mvvm (Model-View-ViewModel )
Model:模型层,负责处理业务逻辑以及和服务器端进行交互
View:视图层:负责将数据模型转化为UI展示出来,可以简单的理解为HTML页面
ViewModel:视图模型层,用来连接Model和View,是Model和View之间的通信桥梁
2.组件化开发
把一整个页面拆成各个不同的组件,然后再整合在一起,实现各个功能,布局的隔离,降低整个系统的耦合度
调试方便,因为不同的功能布局是分离的在出现问题的时候就可以通过错误快速的定位源头,方便快捷的查找排查错误
提高可维护性和复用性,每个组件的职责是单一的
3.丰富的指令系统
指令 (Directives) 是带有 v- 前缀的特殊属性作用:当表达式的值改变时,将其产生的连带影响,响应式地作用于 DOM
常用的vue指令有:
v-model,双向数据绑定v-on(@),监听事件v-bind(:),绑定属性v-for:列表循环渲染v-if:条件渲染
前端路由原理
前端路由的核心就是,访问不同的地址,对应切换不同的组件显示不同的内容,而不是重新加载刷新页面
vue-router就是把组件一一对应的映射到路由地址上,然后渲染出来
主要有三种模式
history 在url地址的后面是以 / 分隔的,但是需要和后端配合进行配置,不然用户访问的页面就是404
hash 在url的后面是以 # 分隔的,比较丑,不美观,这也是路由的默认模式,一般会在开发的时候使用,在上线的时候可以把模式改为history好看一点
abstract 通常用于非浏览器环境,例如在服务器端渲染 (SSR) 中。
什么是mvvm?优缺点
MVVM 表示的是 Model-View-ViewModel
Model:模型层,负责处理业务逻辑以及和服务器端进行交互
View:视图层:负责将数据模型转化为UI展示出来,可以简单的理解为HTML页面
ViewModel:视图模型层,用来连接Model和View,是Model和View之间的通信桥梁, ViewModel 负责监听 Model 的变化并更新 View,实现数据和视图之间的双向数据绑定,就像前面介绍vue的时候说的一样用户只需要把重点放在操作数据上面,而不是去操作dom
工厂函数与构造函数的区别
- 工厂函数没有共享原型
- 工厂函数需要手动
return - 构造函数是通过
new关键字创建
在vue2中是如何监听数组的变化
在Vue2中,Vue提供了一种称为”==数组变异方法==”的机制,用于监听数组的变化。这些变异方法包括
1.push、数组尾部添加,返回修改i后数组长度
2.pop、数组尾部删除,返回删除的数据
3.shift、数组头部删除,返回删除的元素
4.unshift、数组头部添加,返回新数组长度
5.splice、删除数组任意位置元素
splice(删除元素对应位置的索引,删除的个数[不填默认从头部开始删除],新增的元素) ,返回值:删除的元素数组
6.sort 数组排序
7.reverse 数组翻转
当你使用这些方法修改数组时,Vue能够检测到变化并及时更新视图
Vue的数组变异方法通过重写数组的原型方法来实现。当你调用这些方法时,Vue会在修改数组之前和之后执行一些特定的逻辑,以便通知相关的依赖(比如视图)
以下是一个简单的例子,演示了如何在Vue2中监听数组的变化:
1 | <html lang="cn"> |
在上面的例子中,当点击按钮时,addItem 方法会使用数组变异方法 push 向 items 数组中添加一个新的元素。由于Vue监听了这个数组的变化,它会在数组被修改后自动更新相关的视图,使新的元素在页面上显示出来。
需要注意的是,Vue对数组变异的监听仅限于这些特定的数组变异方法,直接通过索引修改数组的元素或修改 length 属性的方式是无法被Vue检测到的。如果你需要监听这些非变异操作,可以使用 Vue.set 方法或 vm.$set 方法
有没有了解虚拟列表
虚拟列表(Virtual List)是一种优化长列表渲染性能的技术。当需要展示大量数据时,传统的方式是将所有数据都渲染到DOM中,这可能导致页面加载缓慢、占用大量内存和性能下降。虚拟列表通过只渲染用户当前可见的部分数据,以及根据滚动位置动态加载和卸载列表项,来减轻这些问题。
基本思想是只渲染视口(可见区域)内的数据项,而不是整个数据集。这可以通过以下几个关键概念来实现:
- 可视区域(Viewport): 用户当前看到的部分页面。在虚拟列表中,只有可视区域内的数据项会被真正渲染到DOM中。
- 滚动监听: 监听滚动事件,以确定用户浏览的位置。当用户滚动时,虚拟列表会相应地更新可视区域的内容。
- 动态加载和卸载: 根据滚动位置,动态加载进入可视区域的数据项,同时卸载离开可视区域的数据项,以保持DOM的轻量级。
虚拟列表的优势在于减少了初始加载时的渲染压力,提高了页面的响应速度。这对于处理大型数据集的情况非常有用,比如在前端框架 (如Vue、React等)中使用虚拟列表来渲染大量的列表数据。
实现虚拟列表的方式可以有多种,具体的实现可能依赖于所用的前端框架或库。许多现代前端框架都提供了虚拟列表的支持或者有相关的第三方库。
vue2中element-ui的自动按需导入
1. 安装 babel-plugin-import 插件
在项目中安装 babel-plugin-import 插件:
1 | npm install babel-plugin-import -D |
2. 配置 .babelrc 文件
在项目根目录下创建 .babelrc 文件,配置插件:
1 | { |
3. 在 main.js 中引入 Element UI 样式
在你的 main.js 文件中引入 Element UI 的样式:
1 | import 'element-ui/lib/theme-chalk/index.css'; |
libraryName 配置
libraryName 选项通常用于指定按需加载的组件库的名称。对于 babel-plugin-import 插件,它的配置对象中还有一些其他可用的选项,可以根据需要进行配置。以下是一些常见的选项:
- libraryName (字符串,必需): 用于指定要按需加载的组件库的名称,即插件将按照这个名称来寻找组件并进行按需加载。
- libraryDirectory (字符串,默认为 “lib”): 用于指定组件库源代码的目录,通常是包含组件定义的目录。这是相对于组件库的主目录的路径。
- style (布尔值或函数,默认为 true): 是否同时导入样式文件。如果设置为
true,插件将尝试导入样式文件;如果设置为false,则只导入 JavaScript 文件。你还可以提供一个函数,根据需要返回样式文件路径。 - camel2DashComponentName (布尔值,默认为 true): 是否将组件名从驼峰式转为短横线形式。例如,
MyComponent可以被转换为my-component。
这里是一个示例配置:
1 | { |
图片懒加载实现
图片的加载是由
src引起的,当对src赋值时,浏览器就会请求图片资源。根据这个原理,我们使用HTML5的data-xxx属性来储存图片的路径,在需要加载图片的时候,将data-xxx中图片的路径赋值给src,这样就实现了图片的按需加载,即懒加载。注意:
data-xxx中的xxx可以自定义,这里我们使用data-src来定义。懒加载的实现重点在于确定用户需要加载哪张图片,在浏览器中,可视区域内的资源就是用户需要的资源。所以当图片出现在可视区域时,获取图片的真实地址并赋值给图片即可。
使用原生
JavaScript实现懒加载:
知识点:
(1)window.innerHeight是浏览器可视区的高度
(2)document.body.scrollTop || document.documentElement.scrollTop是浏览器滚动的过的距离
(3)imgs.offSetTop是元素顶部距离文档顶部的高度(包括滚动条的距离)
(4)图片加载条件:img.offSetTop < window.innerHeight + document.body.scrollTop;
vue-cli基于webpack底层封装了mode,环境变量配置(开发或是生产环境),可以实现手动配置选项覆盖
css选择器优先级
- !important(在属性后面写上这条样式,会覆盖掉页面上任何位置定义的元素的样式。)
- 行内样式,在style属性里面写的样式。
- id选择器
- class选择器
- 标签选择器
- 通配符选择器
- 浏览器的自定义属性和继承
可继承的属性有哪些
以下是一些常见的可继承属性:
- 文本属性(Text Properties):
color:文本颜色font:字体系列、字体大小等font-family:字体系列font-size:字体大小font-style:字体样式(正常、斜体等)font-weight:字体粗细
- 行高属性(Line Height Properties):
line-height:行高
- 列表属性(List Properties):
list-style:列表样式类型、位置等list-style-type:列表项标志的类型list-style-position:列表项标志的位置list-style-image:用作列表项标志的图像
- 表格布局属性(Table Layout Properties):
border-collapse:表格边框的折叠方式border-spacing:表格边框的间距
- 用户界面属性(User Interface Properties):
cursor:鼠标指针样式
- 可见性属性(Visibility Properties):
visibility:元素的可见性
- 生成内容属性(Generated Content Properties):
content:用于 ::before 和 ::after 伪元素的生成内容
- 光标属性(Cursors Properties):
cursor:光标类型
需要注意的是,并非所有的属性都是可继承的。例如,width、height等尺寸相关的属性就不是可继承的
清除浮动
使用clearfix(清除浮动的伪元素):
这是一种常见的清除浮动的方法,通过在父元素上应用伪元素清除浮动。
1
2
3
4
5
6
7
8
9.clearfix::after {
content: "";
display: table;
clear: both;
}
.clearfix {
*zoom: 1; /* 兼容IE */
}在父元素上添加
clearfix类,这样就会在父元素最后插入一个空的块级元素,该元素通过clear: both;规则清除浮动。使用overflow属性:
将父元素的
overflow属性设置为auto或hidden也可以触发 BFC(块级格式化上下文),从而清除浮动。1
2
3.parent {
overflow: hidden; /* 或 overflow: auto; */
}这样设置会创建一个新的 BFC,使得父元素包含浮动的子元素。
盒子居中方法
1.flex布局
2.脱标,利用margin自动实现居中
3.利用位移和定位
定位移动的距离参考的父级的大小
位移移动参考的距离是自己自身的大小
利用父相子绝,向右位移50%,向下位移50%,因为定位参考的大小是父级,这时就会超出了
向上反方向位移自身大小的50%这时子盒子就会居中显示
自定义指令的生命周期
bind:
- 当指令被第一次绑定到元素时触发。在这个阶段,你可以执行一次性的初始化设置。
1
2
3
4
5Vue.directive('custom-directive', {
bind(el, binding, vnode) {
// 在绑定时执行一次性的初始化设置
}
});inserted:
- 当被绑定元素插入到 DOM 中时触发。通常用于执行初始化操作,比如获取焦点。
1
2
3
4
5Vue.directive('custom-directive', {
inserted(el, binding, vnode) {
// 在元素插入到 DOM 时执行初始化操作
}
});update:
- 在包含组件的 VNode 更新时触发,但可能在其子 VNode 更新之前。
1
2
3
4
5Vue.directive('custom-directive', {
update(el, binding, vnode, oldVnode) {
// 在组件的 VNode 更新时触发
}
});componentUpdated:
- 在包含组件的 VNode 及其子 VNode 全部更新后触发。
1
2
3
4
5Vue.directive('custom-directive', {
componentUpdated(el, binding, vnode, oldVnode) {
// 在组件的 VNode 及其子 VNode 全部更新后触发
}
});unbind:
- 在指令与元素解绑时触发。可以执行一些清理工作。
1
2
3
4
5Vue.directive('custom-directive', {
unbind(el, binding, vnode) {
// 在解绑时执行清理工作
}
});
你在vue中给key添加一个属性,但是DOM没有刷新
- 如果你在对象或数组上新增属性或元素,Vue 也无法检测到变化。
1
2
3
4
5
6
7
8
9
10
11data() {
return {
myArray: [1, 2, 3]
};
},
methods: {
addElement() {
// 这样新增的元素不会触发响应式更新
this.myArray.push(4);
}
}解决方法: 同样,使用
Vue.set方法或者扩展运算符来确保变化被观察到。1
2
3
4
5// 使用 Vue.set
Vue.set(this.myArray, this.myArray.length, 4);
// 或者使用扩展运算符
this.myArray = [...this.myArray, 4];
依赖注入
provide 选项:
provide选项允许你指定一个对象,其中包含你想要提供给后代组件的属性或方法。
1
2
3
4
5
6
7
8
9
10// ParentComponent.vue
export default {
provide: {
message: 'Hello from parent!',
showMessage: function() {
alert('Hello!');
}
},
// ...
}inject 选项:
inject选项用于接收祖先组件通过provide提供的值。
1
2
3
4
5
6
7
8
9// ChildComponent.vue
export default {
inject: ['message', 'showMessage'],
created() {
console.log(this.message); // 'Hello from parent!'
this.showMessage(); // Alert: 'Hello!'
},
// ...
}你还可以使用对象语法来更详细地配置注入:
1
2
3
4
5
6
7
8
9
10
11
12// ChildComponent.vue
export default {
inject: {
message: { default: 'Default message' },
showMessage: { default: () => {} }
},
created() {
console.log(this.message); // 'Hello from parent!' 或者 'Default message'(如果没有被提供)
this.showMessage(); // 执行提供的函数,或者是空函数(如果没有被提供)
},
// ...
}
前端路由两个形式
hash
history
给你一个数组实现去重
使用 Set(ES6):
- Set 是一种集合类型,它只允许存储唯一的值,因此可以用来快速去重数组。
1
2
3const array = [1, 2, 3, 4, 4, 5, 5, 6];
const uniqueArray = [...new Set(array)];
console.log(uniqueArray);使用 filter 方法:
- 使用
filter方法结合indexOf或includes方法来筛选出不重复的元素。
1
2
3
4
5const array = [1, 2, 3, 4, 4, 5, 5, 6];
const uniqueArray = array.filter((value, index, self) => {
return self.indexOf(value) === index;
});
console.log(uniqueArray);或者使用
includes:1
2
3
4
5const array = [1, 2, 3, 4, 4, 5, 5, 6];
const uniqueArray = array.filter((value, index, self) => {
return self.includes(value);
});
console.log(uniqueArray);- 使用
使用 reduce 方法:
- 使用
reduce方法来构建一个新数组,只添加第一次出现的元素。
1
2
3
4
5
6
7
8const array = [1, 2, 3, 4, 4, 5, 5, 6];
const uniqueArray = array.reduce((accumulator, currentValue) => {
if (!accumulator.includes(currentValue)) {
accumulator.push(currentValue);
}
return accumulator;
}, []);
console.log(uniqueArray);- 使用
使用 Map 数据结构:
- 使用 Map 数据结构来存储数组中的唯一值。
1
2
3const array = [1, 2, 3, 4, 4, 5, 5, 6];
const uniqueArray = Array.from(new Map(array.map(item => [item, item])).values());
console.log(uniqueArray);
computed和watch的区别
computed计算属性具有==缓存的特性==,当我们初次访问的时候会把数据缓存起来,下次访问直接在缓存里面直接取,只有当依赖的数据发生变化时才会重新计算,它会返回一个经过==计算之后的值==,并且是只能==执行同步任务==
而watch起到的是一个观察的作用==监听数据的变化==,当监听的数据发生变化时就会,执行自定义的回调函数,它==没有返回值==,是可以==执行异步任务==,例如发起异步的ajax请求
对SPA的理解
SPA(single-page application)翻译过来就是单页面应用程序,是一种网络应用程序或是网站的模型,它是通过动态的重写当前页面来实现与用户之间的交互,避免了页面之间的切换跳转打断用户的体验,所有页面上的资源和内容都是在用户点击访问的时候按需加载,在任何时候都不会重新加载页面
优点:
- 有桌面应用端的快速访问的及时性和高效性
- 用户体验好,用户切换页面是不会重新加载整个页面
- 良好的前后端分离,分工更加明确
缺点:
- 首屏加载速度慢
- 只有一个html页面不利于seo搜索引擎抓取
解决首屏加载慢问题
1.减少入口文件的体积
2.静态资源本地缓存
3.ui框架的按需加载,不要使用全局导入
4.使用路由懒加载,只有在用户访问的时候才加载对应的页面内容
5.使用SSR,使用SSR可以在服务器端预先渲染页面,减少客户端渲染时间,提高页面加载速度和性能
6.组件重复打包,将SPA中重复使用的组件进行打包,避免重复加载相同的代码,减少服务器响应时间和带宽占用
v-show和v-if怎么理解
都是依据条件来选择性的决定是否显示dom元素
v-show是通过动态的设置css的display: none/block 来显示隐藏dom元素,dom元素还是在页面上的,占据位置
应用场景是页面的元素切换显示隐藏比较频繁,模态框的显示隐藏
v-if是设置依据条件,创建或是销毁dom元素,销毁了后页面上是没有dom元素的,相较于v-show开销更加大
应用场景一般用在初始状态就是显示或是隐藏,在进入页面后**检查用户是否登录**
聊一聊vue的生命周期
概念: vue实例从创建到销毁的整个过程就叫作生命周期
生命周期主要有四个阶段八个钩子函数分别是
| 生命周期钩子 | 阶段 | 描述 |
|---|---|---|
| beforeCreate | 创建前 | 组件实例还未创建,常用于插件开发的一些初始化任务 |
| created | 创建后 | 组件初始化完毕,可以获取数据使用,常用于发起ajax的异步数据请求 |
| beforeMount | 挂载前 | dom已被初始化,但并未挂载和渲染 |
| mounted | 挂载后 | dom已完成挂载和渲染,可用于访问数据和操作页面的dom元素 |
| beforeUpdate | 更新前 | 数据已被更新,但页面数据并未更新 |
| updated | 更新后 | 数据已更新完毕 |
| beforeDestroy | 销毁前 | 实例销毁前,实例目前实例仍然可用,常用于一些定时器的清除 |
| destroyed | 销毁后 | 实例已被销毁完毕 |
题外话:数据请求在created和mounted的区别
created是在组件实例一旦创建完成的时候立刻调用,这时候页面dom节点并未生成;mounted是在页面dom节点渲染完毕之后就立刻执行的。触发时机上created是比mounted要更早的
两者的相同点:都能拿到实例对象的属性和方法。
讨论这个问题本质就是触发的时机,放在mounted中的请求时间超时就会造成页面渲染阻塞或是造成白屏的状况(因为此时页面dom结构已经生成),但如果在页面加载前完成请求,则不会出现此情况。建议对页面内容的改动放在created生命周期当中
vue实例挂载的过程中发生了什么
首先找到vue的构造函数
源码位置:src\core\instance\index.js
1 | function Vue (options) { |
options是用户传递过来的配置项,如data、methods等常用的方法
vue构建函数调用_init方法,但我们发现本文件中并没有此方法,但仔细可以看到文件下方定定义了很多初始化方法
1 | initMixin(Vue); // 定义 _init |
首先可以看initMixin方法,发现该方法在Vue原型上定义了_init方法
源码位置:src\core\instance\init.js
1 | Vue.prototype._init = function (options?: Object) { |
仔细阅读上面的代码,我们得到以下结论:
- 在调用
beforeCreate之前,数据初始化并未完成,像data、props这些属性无法访问到 - 到了
created的时候,数据已经初始化完成,能够访问data、props这些属性,但这时候并未完成dom的挂载,因此无法访问到dom元素 - 挂载方法是调用
vm.$mount方法
initState方法是完成props/data/method/watch/methods的初始化
源码位置:src\core\instance\state.js
1 | export function initState (vm: Component) { |
我们和这里主要看初始化data的方法为initData,它与initState在同一文件上
1 | function initData (vm: Component) { |
仔细阅读上面的代码,我们可以得到以下结论:
- 初始化顺序:
props、methods、data data定义的时候可选择函数形式或者对象形式(组件只能为函数形式)
关于数据响应式在这就不展开详细说明
上文提到挂载方法是调用vm.$mount方法
源码位置:
1 | Vue.prototype.$mount = function ( |
阅读上面代码,我们能得到以下结论:
- 不要将根元素放到
body或者html上 - 可以在对象中定义
template/render或者直接使用template、el表示元素选择器 - 最终都会解析成
render函数,调用compileToFunctions,会将template解析成render函数
对template的解析步骤大致分为以下几步:
- 将
html文档片段解析成ast描述符 - 将
ast描述符解析成字符串 - 生成
render函数
生成render函数,挂载到vm上后,会再次调用mount方法
源码位置:src\platforms\web\runtime\index.js
1 | // public mount method |
调用mountComponent渲染组件
1 | export function mountComponent ( |
阅读上面代码,我们得到以下结论:
- 会触发
beforeCreate钩子 - 定义
updateComponent渲染页面视图的方法 - 监听组件数据,一旦发生变化,触发
beforeUpdate生命钩子
updateComponent方法主要执行在vue初始化时声明的render,update方法
1 | render`的作用主要是生成`vnode |
源码位置:src\core\instance\render.js
1 | // 定义vue 原型上的render方法 |
_update主要功能是调用patch,将vnode转换为真实DOM,并且更新到页面中
源码位置:src\core\instance\lifecycle.js
1 | Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) { |
三、结论
new Vue的时候调用会调用_init方法- 定义
$Set``、$get、$delete、$watch等方法 - 定义
$on、$off、$emit、$off等事件 - 定义
_update、$forceUpdate、$destroy生命周期
- 定义
- 调用
$mount进行页面的挂载 - 挂载的时候主要是通过
mountComponent方法 - 定义
updateComponent更新函数 - 执行
render生成虚拟DOM _update将虚拟DOM生成真实DOM结构,并且渲染到页面中
为什么不建议v-for和v-if一起用
v-if用于条件性的渲染页面dom元素
v-for遍历数组循环渲染列表数据
v-for的优先级比v-if要高,会先执行页面的循环渲染再依据v-if的条件选择性的渲染对应的元素,若是初次v-for循环渲染的时候有不符合条件的元素就会被渲染出来再依据v-if的条件来判断是否删除和创建元素,这样就会造成不必要的性能损耗
所以永远不要把v-if和v-show放在同一个元素上
如果必须要使用可以使用计算属性先把每个元素依据条件过滤一遍再执行渲染
为什么data属性是一个函数而不是对象
保持数据私有化,避免数据污染,如果data是一个普通的对象,当你创建多个相同的组件实例的时候,他们就会共享同一个数据对象,当你修改其中一个组件实例的数据是另外一个也会被修改,这样就会造成影响
如果是一个函数,当组件被创建的时候,函数被调用,返回的是一个新的数据对象,这样每一个组件的初始数据都是不一样的,保持数据的一个私有化,修改一个另外一个不会被影响到
组件间的通信方式
组件通讯可以分为组件和通讯两部分来理解
组件:每一个.vue文件都可以理解为是一个组件
通讯:是指以某种方式或是以某种手段来实现信息的传递或者是交互
每一个vue文件都有自己独立的作用域,组件之间的数据无法实现数据之间的共享,而我们在开发的时候有这种需求,组件通讯的目的就是实现组件之间数据的共享,把各个组件构成一个完整的有机的整体
组件之间的关系主要有父子关系和非父子关系
父子组件之间的通讯
父向子传值
父向子传递父组件绑定一个自定义属性向子组件传递数据,子组件就可以使用props属性接收到传递过来的数据,进行页面渲染
子向父传值
子向父传递数据使用$emit触发一个自定义事件,并传递数据,父组件监听到这个自定义事件就可以获取到这个数据,来操作获取到的数据
非父子组件之间的传值
兄弟之间
事件总线eventbus,一方传递数据$emit触发自定义事件并携带数据,另一方就可以使用$on监听到自定义事件和传递过来的数据
1 | parent |
复杂组件
复杂的组件之间的通信推荐使用vuex,开发实际中使用的也是比较多的
1 | this.parent$emit() |
vue双向绑定的理解及原理
Vue.js 是采用数据劫持结合发布者-订阅者模式的方式,通过 Object.defineProperty()来劫持各个属性的 setter,getter,在数 据变动时发布消息给订阅者,触发相应的监听回调。
主要分为以下几 个步骤:
需要 observe 的数据对象进行递归遍历,包括子属性对象的属性, 都加上 setter 和 getter 这样的话,给这个对象的某个值赋值,就会 触发 setter,那么就能监听到了数据变化
compile 解析模板指令,将模板中的变量替换成数据,然后初始化 渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数 据的订阅者,一旦数据有变动,收到通知,更新视图
Watcher 订阅者是 Observer 和 Compile 之间通信的桥梁,主要做 的事情是:
①在自身实例化时往属性订阅器(dep)里面添加自己
② 自身必须有一个 update()方法 ③待属性变动 dep.notice()通知时, 能调用自身的 update()方法,并触发 Compile 中绑定的回调,则功成身退。
- MVVM 作为数据绑定的入口,整合 Observer、Compile 和 Watcher 三者,通过 Observer 来监听自己的 model 数据变化,通过 Compile 来解析编译模板指令,最终利用 Watcher 搭起 Observer 和 Compile 之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据 model 变更的双向绑定效果
谈谈你对 $nextTick 的理解
vue在更新dom的时候是异步的,当数据发生变化的时候就会开启一个异步更新队列,页面视图需要等待队列中所有的数据完成变化之后再统一进行更新
如果没有$nextTick那么每次修改数据都会触发页面视图的更新,有了$nextTick机制就只需要更新一次,本质上也是对性能的一种优化策略
使用场景:在修改数据后想要立即得到修改后的dom元素,或者是一进入页面就要对搜索框获取到焦点,就可以使用
slot的理解,应用场景
slot艺名叫做插槽,花名“占坑”,可以对组件内容进行个性化的diy定制,当我们使用组件的时候不会所有的组件的内容都是符合我们业务的需求,这个时候我门就需要使用插槽来完成我们的开发需求
应用场景
当我们的父组件在使用一个复用组件的时候,仅仅只需要修改一小部分内容,那我们再去重写一个一样的显然是不明智的,通过slot插槽向不同的位置分发不同的内容,实现组件在不同场景下的应用
三种插槽
默认插槽
在子组件内使用slot标签来占位置,也可以在slot的标签内写入内容,这会作为标签的后备内容,如果父组件没有传递内容,就会显示设置的默认值,
具名插槽
顾名思义就是有名字的插槽
在子组件上使用name属性给插槽起一个名字(不填为默认插槽),父组件在分发内容的使用,v-slot=属性名,来向子组件内分发指定的内容
作用域插槽
作用域插槽其实就时可以带数据的插槽,即可以携带参数的插槽
简单的来说就是子组件提供给父组件的参数,该参数仅限于插槽中使用,父组件可根据子组件传过来的插槽数据来进行不同的方式展现和填充插槽内容。
基本使用步骤:
- 在子组件的 slot 标签上使用自定义属性,携带数据传递给父组件
- 父组件使用 template 配合 v-slot 获取传递过来的数据
1 | <td> |
vue.observable 你有了解过吗?
对vue中key的理解
v-for数组循环列表给每一项添加一个唯一标识,主要是为了更加高效的更新dom元素,在没有key属性的时候,更新和改变数据的时候会将整个列表全部重新渲染,浪费性能
v-for默认采用的是就地复用的原则,当列表数据发生变化的时候,他会根据key属性去判断某一项到底是不是需要被修改,如果需要修改就直接渲染这一项否则就会复用之前的
对keep-alive的理解,如何缓存当前组件、缓存后如何更新
路由之间在切换的时候对应的组件就会被销毁和创建,这样就会导致状态丢失,keep-alive主要目的就是保持组件的状态,确保组件在销毁时不会丢失数据和状态而是把它缓存起来
使用:
使用
有三个属性:
- include:组件名数组,只有被匹配中的组件才会被缓存起来
- exclude:组件名数组,任何被匹配中的组件都不会被缓存
- max ,数字,最多缓存多少组件
keep-alive会触发两个生命周期函数
- activated,在进入组件的时候触发
- deactivated,在离开组件的时候触发
组件在被缓存后就不会有created,beforemount,mounted 钩子函数了,只会有在进入页面的时候的那一次,所以提供了activated和deactivated钩子函数来帮我们实现业务需求
keep alive原理
vue常用修饰符,应用场景
表单修饰符
.lazy
.trim 去除表单首尾的空格
.number 将用户输入的值转换为数字类型
事件修饰符
.stop 阻止事件冒泡
.prevent 阻止默认行为
.once 绑定事件后只会触发一次
按键修饰符
.enter
.tab
.esc
….
v-bind修饰符
.sync 数据的双向绑定
你有写过自定义指令吗?应用场景
vue的核心就是由数据驱动视图,为了方便的实现数据驱动视图,vue设计了一些内置的由v-开头的指令来实现不同的功能。像常用的有v-model的双向数据绑定,v-bind的数据绑定,v-if,v-else的数据的条件渲染等等
但是有的时候并不是所有的指令都满足我们的需求,vue也是支持我们自己自定义指令的,实现个性化的需求
组件的注册又分为全局注册和局部注册
全局注册
全局注册在main.js里面使用Vue.directive方法进行注册,该方法会接受两个参数,一个是要自定义的指令的名字,一个是指令的配置对象配置对象里面会有一个insered指令的钩子函数会在被插入到dom树上时自动执行,并把绑定了该指令的对象传递过来,我们就可以对该元素进行一些你自己想要的一些自定义需求
局部注册
局部注册在组件的options选项中设置directives属性,和全局注册差不多,里面有自定义的指令名,和配置对象,等绑定了自定义指令的元素被插入到dom树上面的时候对它进行你自己想要的自定义操作
应用场景
封装一个v-focus在初始一进入页面时就获取到input框的一个焦点
1 | // Vue.directive(指令名,配置对象) |
或者是封装一个v-throttle的一个阻止表单重复提交的一个自定义指令
1 | // 1.设置v-throttle自定义指令 |
权限校验自定义指令
vue中的过滤器了解过吗?应用场景
什么是虚拟DOM?如何实现一个虚拟DOM
虚拟 DOM 的解析过程:
首先对将要插入到文档中的 DOM 树结构进行分析,使用 js 对象将 其表示出来,比如一个元素对象,包含 TagName、props 和 Children 70 这些属性。然后将这个 js 对象树给保存下来,最后再将 DOM 片段 插入到文档中
当页面的状态发生改变,需要对页面的 DOM 的结构进行调整的时候, 首先根据变更的状态,重新构建起一棵对象树,然后将这棵新的对象 树和旧的对象树进行比较,记录下两棵树的的差异
最后将记录的有差异的地方应用到真正的 DOM 树中去,这样视图就更新了
了解diff算法吗?
在新老虚拟 DOM 对比时:
首先,对比节点本身,判断是否为同一节点,如果不为相同节点,则删除该节点重新创建节点进行替换 如果为相同节点,进行 patchVnode,判断如何对该节点的子节点进行处理
先判断一方有子节点一方没有子节点的情况(如果新的 children 没有子节点,将旧的子节点移除)
比较如果都有子节点,则进行 updateChildren,判断如何对这些新 老节点的子节点进行操作(diff 核心)
匹配时,找到相同的子节点,递归比较子节点 在 diff 中,只对同层的子节点进行比较,放弃跨级的节点比较,使得时间复杂从 O(n 3)降低值 O(n),也就是说,只有当新旧 children 都为多个子节点时才需要用核心的 Diff 算法进行同层级比较
vue2及vue3的区别
- 性能优化:
- Vue 3引入了响应式系统的重大改进,通过Proxy实现了更高效的响应式数据追踪,从而提高了性能。
- Vue 3的编译器生成的代码更小,运行时性能更好,使应用程序加载更快。
- Composition API:组合API:
- Vue 3引入了
Composition API,这是一种新的API风格,使得组件的逻辑更易于组织和重用。Composition API允许开发者按照功能划分代码,而不是像Vue 2那样按照选项的顺序。
- Vue 3引入了
- 全局 API的修改:
- 在Vue 3中,全局API发生了一些变化,例如
Vue.component变成了app.component,Vue.directive变成了app.directive等。这是为了更好地支持模块化的开发方式。
- 在Vue 3中,全局API发生了一些变化,例如
- Teleport:传送:
- Vue 3引入了Teleport组件,用于更灵活地在DOM中的不同位置渲染组件,这在处理模态框等场景时非常有用。
- Fragment和多根节点:
- Vue 3允许组件返回多个根节点,而Vue 2要求组件有且只有一个根节点。Vue 3还引入了Fragment语法,使得在模板中使用多个根节点更加方便。
- 动态属性:
- 在Vue 3中,可以使用
v-bind绑定动态的属性名,而在Vue 2中需要使用v-bind和v-on的结合来实现。
- 在Vue 3中,可以使用
vue项目本地开发完成后部署到服务器后报404是什么原因呢?
项目使用history需要后端搭配进行配置,当我们在地址栏输入 www.xxx.com 时,这时会打开我们 dist 目录下的 index.html 文件,然后我们在跳转路由进入到 www.xxx.com/login
关键在这里,当我们在 website.com/login 页执行刷新操作,nginx location 是没有相关配置的,所以就会出现 404 的情况
修改规则无论我们访问任何页面都会重定向到index.html
你是怎么处理vue项目中的错误的?
父子组件的生命周期
1.加载渲染过程
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
2.子组件更新过程
父beforeUpdate->子beforeUpdate->子updated->父updated
3.父组件更新过程
父beforeUpdate->父updated
4.销毁过程
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
vue如何监听对象或者数组某个属性的变化
在Vue中,你可以使用”watch”特性来监听对象或数组中某个属性的变化。对于对象,你可以使用$watch方法,而对于数组,你可以使用$watch方法或者直接使用Vue.Set来确保数组变动也被观察到。以下是一些示例:
对象属性的监听
1 | <template> |
在上述例子中,通过watch选项,我们监听了user.name的变化。
数组元素的监听
使用 $watch
1 | <template> |
使用 Vue.Set
1 | <template> |
在这两个数组的例子中,我们通过watch选项监听了整个数组的变化。如果你需要监听特定元素的变化,你可以使用更深层次的属性路径,就像在对象属性监听的例子中一样。
assets和static的区别
相同点: assets 和 static 两个都是存放静态资源文件。项目中所 需要的资源文件图片,字体图标,样式文件等都可以放在这两个文件下
不相同点:assets 中存放的静态资源文件在项目打包时,也就是运 行 npm run build 时会将 assets 中放置的静态资源文件进行打包 上传,所谓打包简单点可以理解为压缩体积,代码格式化。而压缩后 的静态资源文件最终也都会放置在 static 文件中跟着 index.html 一同上传至服务器。
static 中放置的静态资源文件就不会要走打包 压缩格式化等流程,而是直接进入打包好的目录,直接上传至服务器。 因为避免了压缩直接进行上传,在打包时会提高一定的效率,但是 static 中的资源文件由于没有进行压缩等操作,所以文件的体积也 就相对于 assets 中打包后的文件提交较大点。在服务器中就会占据 更大的空间。
建议:
将项目中 template 需要的样式文件 js 文件等都可以放置在 assets 中,走打包这一流程。减少体积。
而项目中引入的第三方的 资源文件如 iconfoont.css 等文件可以放置在 static 中,因为这 些引入的第三方文件已经经过处理,不再需要处理,直接上传。
VueRouter是什么, 有那些组件
router和route的区别
route相当于正在跳转的路由对象,可以从route里面获取[hash],name ,path,query,matched等属性方法
router 是VueRouter的实例,router是一个全局的路由对象,里面有很多的属性和方法 ,比如:router.push,route.options等等
路由开发的优缺点
优点:
● 整体不刷新页面,用户体验更好
● 数据传递容易, 开发效率高
缺点:
●开发成本高(需要学习专门知识)
●首次加载会比较慢一点。不利于seo
VueRouter的使用方式
1使用Vue.use( )将VueRouter插入
2创建路由规则
3创建路由对象
4将路由对象挂到 Vue 实例上
5设置路由挂载点
路由跳转有那些方式
通过
this.$router.push方法:- 在Vue组件中,你可以通过
this.$router.push方法进行编程式的导航。可以传递一个路径或一个描述地址的对象。
1
2
3
4
5// 字符串路径
this.$router.push('/path');
// 对象形式
this.$router.push({ path: '/path' });该方法会导致路由的切换,类似于用户点击浏览器的前进或后退按钮。
- 在Vue组件中,你可以通过
通过
this.$router.replace方法:- 与
push方法类似,但是不会留下历史记录,不会在浏览器的历史堆栈中创建新的记录。
1
this.$router.replace('/path');
- 与
通过
this.$router.go方法:- 用于在浏览器的历史记录中前进或后退指定步数。可以传递一个负数表示后退,正数表示前进。
1
2this.$router.go(-1); // 后退一步
this.$router.go(1); // 前进一步
编程式导航使用的方法以及常用的方法
使用
$router.push:$router.push方法用于向 history 栈添加一个新的记录,然后导航到该记录。它接受一个字符串路径或一个描述地址的对象。
1
2
3
4// 字符串路径
this.$router.push('/path');
// 对象形式
this.$router.push({ path: '/path' });使用
$router.replace:$router.replace方法与$router.push类似,但是它不会留下历史记录,而是替换当前的记录。
1
this.$router.replace('/path');
使用
$router.go:$router.go方法用于在浏览器的历史记录中前进或后退指定步数。可以传递一个负数表示后退,正数表示前进。
1
2this.$router.go(-1); // 后退一步
this.$router.go(1); // 前进一步使用
$router.back和$router.forward:$router.back方法相当于$router.go(-1),用于后退一步。$router.forward方法相当于$router.go(1),用于前进一步。
1
2this.$router.back(); // 后退一步
this.$router.forward(); // 前进一步
路由的传参方式

路由重定向和404
1 匹配path后, 强制切换到另一个目标path上
2 redirect 是设置要重定向到哪个路由路径
3 网页默认打开, 匹配路由”/“, 强制切换到”/find”上
4 redirect配置项, 值为要强制切换的路由路径
5 强制重定向后, 还会重新来数组里匹配一次规则
路由配置项常用的属性及作用
路由配置参数:
path : 跳转路径
component : 路径相对于的组件
name:命名路由
children:子路由的配置参数(路由嵌套)
props:路由解耦
redirect : 重定向路由
路由守卫
全局前置守卫 (
beforeEach):beforeEach全局前置守卫会在路由切换开始前被调用。可以用来进行一些全局的权限校验或导航控制。
1
2
3
4
5
6
7
8router.beforeEach((to, from, next) => {
// 在路由切换前执行一些逻辑
if (to.meta.requiresAuth && !auth.loggedIn) {
next('/login');
} else {
next();
}
});全局解析守卫 (
beforeResolve):beforeResolve全局解析守卫会在导航被确认之前,解析异步组件。它类似于beforeEach,但是在全局后置守卫之前调用。
1
2
3
4
5router.beforeResolve((to, from, next) => {
// 在导航被确认之前执行一些逻辑
// ...
next();
});全局后置守卫 (
afterEach):afterEach全局后置守卫会在路由切换完成后被调用。可以用来进行一些清理或日志记录等操作。
1
2
3
4router.afterEach((to, from) => {
// 在路由切换后执行一些逻辑
// ...
});路由独享守卫 (
beforeEnter):beforeEnter路由独享守卫可以直接在路由配置中定义,仅对该路由生效。
1
2
3
4
5
6
7
8
9const route = {
path: '/example',
component: Example,
beforeEnter: (to, from, next) => {
// 在进入路由前执行一些逻辑
// ...
next();
}
};组件内守卫 (
beforeRouteEnter,beforeRouteUpdate,beforeRouteLeave):- 这些守卫钩子是在组件内部定义的。
beforeRouteEnter在路由进入时调用,beforeRouteUpdate在路由更新时调用,beforeRouteLeave在路由离开时调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17export default {
beforeRouteEnter(to, from, next) {
// 在路由进入时执行一些逻辑
// ...
next();
},
beforeRouteUpdate(to, from, next) {
// 在路由更新时执行一些逻辑
// ...
next();
},
beforeRouteLeave(to, from, next) {
// 在路由离开时执行一些逻辑
// ...
next();
}
};- 这些守卫钩子是在组件内部定义的。
说说你对vuex的理解
- 状态 (State):
- Vuex 的核心就是一个全局的状态存储,即存放所有组件共享的数据。这些数据被称为状态 (state),通常以一个 JavaScript 对象的形式存在。
- 状态的改变 (Mutations):
- 状态的变更必须通过 mutations 进行。mutations 是包含一系列对状态进行操作的方法。每个 mutation 都有一个字符串的事件类型 (type) 和一个回调函数,负责实际修改状态。
- 动作 (Actions):
- Actions 用于处理异步操作,通过提交 mutations 来修改状态。Actions 提供了一种将业务逻辑和异步操作从组件中抽离的方式,使得代码更容易维护和测试。
- 模块 (Modules):
- 为了应对大型应用中的状态管理问题,Vuex 允许将 store 分割成模块 (modules)。每个模块可以有自己的 state、mutations、actions、getters,使得代码组织更加灵活。
- Getter:
- Getters 允许你在访问状态时进行一些计算,类似于 Vue 中的计算属性。它们对 store 中的状态进行派生,返回新的值。
- 单一状态树 (Single State Tree):
- Vuex 使用单一状态树来存储整个应用的状态。这使得状态的变化变得可追踪,方便调试和查看整个应用的状态。
- 严格模式 (Strict Mode):
- Vuex 提供了严格模式,可以在开发环境中检测状态的修改是否是通过 mutations 进行的。这有助于捕获在组件外部直接修改状态的错误。
- 插件 (Plugins):
- Vuex 允许通过插件的方式扩展其功能。你可以编写插件来添加额外的特性,例如日志、持久化存储等。
数据不响应的情况有哪些,如何解决
直接赋值:
- 如果你直接使用
=对一个对象或数组进行赋值,Vue 无法检测到变化。例如:
1
2
3
4
5
6
7
8
9
10
11data() {
return {
myObject: { key: 'value' }
};
},
methods: {
updateObject() {
// 这样的赋值不会触发响应式更新
this.myObject = { newKey: 'newValue' };
}
}解决方法: 使用
Vue.Set方法或者扩展运算符 (…) 来确保对象的属性或数组的元素被观察到。1
2
3
4
5// 使用 Vue.`Set`
Vue.`Set`(this.myObject, 'newKey', 'newValue');
// 或者使用扩展运算符
this.myObject = { ...this.myObject, newKey: 'newValue' };- 如果你直接使用
新增属性或元素:
- 如果你在对象或数组上新增属性或元素,Vue 也无法检测到变化。
1
2
3
4
5
6
7
8
9
10
11data() {
return {
myArray: [1, 2, 3]
};
},
methods: {
addElement() {
// 这样新增的元素不会触发响应式更新
this.myArray.push(4);
}
}解决方法: 同样,使用
Vue.Set方法或者扩展运算符来确保变化被观察到。1
2
3
4
5// 使用 Vue.`Set`
Vue.set(this.myArray, this.myArray.length, 4);
// 或者使用扩展运算符
this.myArray = [...this.myArray, 4];异步更新问题:
- 当在一个异步操作中修改数据时,Vue 也可能无法立即检测到变化。例如,在回调函数中修改数据:
1
2
3
4
5
6
7
8
9
10
11
12
13data() {
return {
message: 'Hello'
};
},
methods: {
asyncUpdate() {
setTimeout(() => {
// 这样的修改可能无法触发响应式更新
this.message = 'Updated Message';
}, 1000);
}
}解决方法: 使用
this.$nextTick来确保在下一次 DOM 更新循环中修改数据。1
2
3
4
5
6
7asyncUpdate() {
setTimeout(() => {
this.$nextTick(() => {
this.message = 'Updated Message';
});
}, 1000);
}
vue.use的原理
Vue.use 是用来注册 Vue.js 插件的方法。当你使用 Vue.use 注册一个插件时,实际上它调用了插件的 install 方法。这个方法可以用来添加全局级别的功能,如全局组件、指令、过滤器,或者向Vue的原型中添加方法。
具体来说,Vue.use 的原理主要包括以下步骤:
检查插件是否已经被安装:
Vue.use方法内部会检查插件是否已经被安装,避免重复注册。
调用插件的
install方法:- 如果插件尚未安装,
Vue.use会调用插件的install方法。这个方法通常在插件的主文件中定义。
1
2
3MyPlugin.install = function(Vue, options) {
// 在这里添加全局功能
};install方法的第一个参数是 Vue 构造函数,第二个参数是插件的选项。你可以在这个方法中添加全局组件、指令、过滤器,或者向Vue的原型中添加方法。- 如果插件尚未安装,
标记插件已安装:
- 一旦插件的
install方法被调用,Vue.use会标记插件已经被安装,避免重复注册。
- 一旦插件的
全局注册组件、指令、过滤器:
- 在
install方法中,你可以利用 Vue 的 API 全局注册组件、指令、过滤器。
1
2
3
4
5
6
7
8
9
10MyPlugin.install = function(Vue, options) {
// 全局注册组件
Vue.component('my-component', MyComponent);
// 全局注册指令
Vue.directive('my-directive', MyDirective);
// 全局注册过滤器
Vue.filter('my-filter', MyFilter);
};- 在
总的来说,Vue.use 的实现非常简单,它主要是通过调用插件的 install 方法来完成插件的注册和安装工作。这样做的好处是可以让插件的使用变得简单而一致,通过一行代码就能完成插件的注册。
mixin的作用,和组件冲突的优先级
mixin 是 Vue 中一种重用组件选项的方式。它允许你在多个组件之间共享组件选项,从而实现代码的复用。mixin 对象可以包含组件选项,如 data、methods、computed 等,以及生命周期钩子。
mixin 的作用:
- 代码复用:
- 通过使用
mixin,你可以将一些组件选项提取出来,使其可以在多个组件中重复使用。这在一些具有相似功能或行为的组件中特别有用。
- 通过使用
- 逻辑分离:
- 将一些通用的逻辑从组件中抽离,通过
mixin进行管理,有助于使组件更加清晰、易于维护。
- 将一些通用的逻辑从组件中抽离,通过
- 动态混入:
mixin可以动态地混入到组件中,实现更灵活的组合方式。
组件和 mixin 冲突的优先级:
当一个组件和一个或多个 mixin 都定义了相同的选项时,它们之间的优先级是有规则的。以下是优先级的规则:
- 全局
mixin:- 如果有全局
mixin,它将首先被应用,其选项将被混入到每个组件中。
- 如果有全局
- 局部
mixin:- 接下来,如果在组件中使用了局部
mixin,那么局部mixin的选项将覆盖全局mixin的选项。
- 接下来,如果在组件中使用了局部
- 组件本身:
- 最后,组件本身的选项将覆盖全局
mixin和局部mixin的选项。
- 最后,组件本身的选项将覆盖全局
这意味着,如果组件和 mixin 定义了相同的选项,组件的定义将具有最高的优先级,其选项将覆盖 mixin 中相同选项的值。
如何强制更新vue组件
vue3
vue3.0的设计目标是什么?做了哪些优化
(1)监测机制的改变 3.0 将带来基于代理 Proxy 的 observer 实现,提供全语言覆盖的 反应性跟踪。
消除了 Vue 2 当中基于 Object.defineProperty 的实现所存在的 很多限制:
(2)只能监测属性,不能监测对象 检测属性的添加和删除; 检测数组索引和长度的变更; 支持 Map、Set、WeakMap 和 WeakSet。
(3)模板 作用域插槽,2.x 的机制导致作用域插槽变了,父组件会重新渲染, 而 3.0 把作用域插槽改成了函数的方式,这样只会影响子组件的重 新渲染,提升了渲染的性能。 同时,对于 render 函数的方面,vue3.0 也会进行一系列更改来方 便习惯直接使用 api 来生成 vdom 。
(4)对象式的组件声明方式 vue2.x 中 的 组 件 是 通 过 声 明 的 方 式 传 入 一 系 列 option, 和 TypeScript 的结合需要通过一些装饰器的方式来做,虽然能实现功 能,但是比较麻烦。 68 3.0 修改了组件的声明方式,改成了类式的写法,这样使得和 TypeScript 的结合变得很容易
(5)其它方面的更改 支持自定义渲染器,从而使得 weex 可以通过自定义渲染器的方式来扩展,而不是直接 fork 源码来改的方式。
支持 Fragment(多个根节点)和 Protal(在 dom 其他部分渲染组件内容)组件,针对一些特殊的场景做了处理。
基于 tree shaking 优化,提供了更多的内置功能。
vue3.0性能的提升主要通过那几个方面体现的
Vue3.0里为什么要用 Proxy API 替代 defineProperty API ?
在 Vue2 中, 0bject.defineProperty 会改变原始数据,而 Proxy 是创建对象的虚拟表示,并提供 Set 、get 和 deleteProperty 等 处理器,这些处理器可在访问或修改原始对象上的属性时进行拦截, 有以下特点∶
不需用使用 Vue.$set 或 Vue.$delete 触发响应式。
全方位的数组变化检测,消除了 Vue2 无效的边界情况。
支持 Map,Set,WeakMap 和 Weakset。
Proxy 实现的响应式原理与 Vue2 的实现原理相同,实现方式大同小 异∶
get 收集依赖
Set、delete 等触发依赖 对于集合类型,就是对集合对象的方法做一层包装:
原方法执行后执 行依赖相关的收集或触发逻辑。
Vue3.0 所采用的 Composition Api 与 Vue2.x 使用的 Options Api 有什么不同?
1. 组织代码的方式:
Options API:
- Options API 使用选项对象(options object)的方式组织代码。在一个组件中,数据、计算属性、方法、生命周期钩子等都被放在一个对象中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21export default {
data() {
return {
message: 'Hello, Vue!',
count: 0
};
},
computed: {
doubleCount() {
return this.count * 2;
}
},
methods: {
increment() {
this.count++;
}
},
mounted() {
console.log('Component mounted');
}
};Composition API:
- Composition API 允许开发者按照功能划分代码,将相关的代码逻辑组织在一起,而不是按照选项的形式组织。每个功能可以通过 ``Set
up函数中的返回值来进行导出和重用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import { ref, computed, onMounted } from 'vue';
export default {
Setup() {
const message = ref('Hello, Vue!');
const count = ref(0);
const doubleCount = computed(() => count.value * 2);
const increment = () => {
count.value++;
};
onMounted(() => {
console.log('Component mounted');
});
return {
message,
count,
doubleCount,
increment
};
}
};- Composition API 允许开发者按照功能划分代码,将相关的代码逻辑组织在一起,而不是按照选项的形式组织。每个功能可以通过 ``Set
2. 响应式数据的声明:
Options API:
- 在 Options API 中,响应式数据通常通过
data方法返回的对象进行声明。
1
2
3
4
5
6data() {
return {
message: 'Hello, Vue!',
count: 0
};
}- 在 Options API 中,响应式数据通常通过
Composition API:
- 在 Composition API 中,可以使用
ref、reactive等函数来声明响应式数据。
1
2
3
4import { ref } from 'vue';
const message = ref('Hello, Vue!');
const count = ref(0);- 在 Composition API 中,可以使用
3. 生命周期钩子:
Options API:
- 在 Options API 中,生命周期钩子直接作为对象的属性进行声明。
1
2
3
4
5
6
7
8
9
10
11export default {
created() {
console.log('Component created');
},
mounted() {
console.log('Component mounted');
},
beforeUnmount() {
console.log('Component will be unmounted');
}
};Composition API:
- 在 Composition API 中,生命周期钩子使用
onXXX的形式进行声明。
1
2
3
4
5
6
7
8
9import { onMounted, onBeforeUnmount } from 'vue';
onMounted(() => {
console.log('Component mounted');
});
onBeforeUnmount(() => {
console.log('Component will be unmounted');
});- 在 Composition API 中,生命周期钩子使用
4. 代码重用:
- Options API:
- 在 Options API 中,代码重用通常通过混入(mixins)来实现,但有时可能会导致命名冲突或复杂性。
- Composition API:
- Composition API 明确支持逻辑的提取和重用,通过将相关逻辑放在一个函数内,并在
Setup中导入和调用。
- Composition API 明确支持逻辑的提取和重用,通过将相关逻辑放在一个函数内,并在
5. Typescript 支持:
- Options API:
- Options API 中的 TypeScript 支持通常需要在组件的选项对象上进行类型声明,有时可能不够直观。
- Composition API:
- Composition API 在 TypeScript 下更直观,通过函数参数的类型推断可以更好地支持类型检查。
说说Vue 3.0中Treeshaking特性?举例说明一下?
Vue 3.0 中引入了 Tree-shaking 特性,这是一项优化技术,用于在构建时剔除未使用的代码,从而减小最终打包文件的体积。Tree-shaking 主要依赖于静态分析,通过分析模块的依赖关系,识别和去除未使用的部分。
在 Vue 3.0 中,Tree-shaking 特性主要表现在以下方面:
- 模块的标记:
- Vue 3.0 的模块系统使用了 ESM(ECMAScript 模块)规范,这使得 JavaScript 引擎能够更好地理解和优化模块的导入和导出。这种标准的模块系统有助于静态分析,提高了 Tree-shaking 的效果。
- 编译时标记:
- Vue 3.0 的编译器在编译阶段会标记出哪些代码是可以被 Tree-shaking 的。这种标记是基于编译时的静态分析,可以准确地识别不会被使用的部分。
举例说明:
考虑以下简单的 Vue 3.0 组件:
1 | <template> |
在这个组件中,有一个未被使用的方法 someUnusedMethod。由于 Vue 3.0 的 Tree-shaking 特性,如果这个方法没有在组件内被使用,那么在构建时它将被剔除,不会出现在最终打包的代码中。
这样,即使你在组件内定义了一些方法或变量,只要它们在实际渲染的过程中没有被使用,它们就不会被包含在最终的打包文件中。这对于减小应用的体积非常有帮助,特别是在大型应用中,很多时候我们可能引入了一些库或组件,但只使用了其中的一部分功能。通过 Tree-shaking,未使用的部分将被自动去除,减小了不必要的资源加载。
用Vue3.0 写过组件吗?如果想实现一个 Modal你会怎么设计?
其他
你了解axios原理吗?有看过源码吗?
SSR解决了什么问题?有做过吗?如何做的
说说vue项目目录结构,若是大型项目如何划分组件及结构
权限管理如何做?控制到按钮级别的权限如何做?
封装自定义权限指令实现按钮级别的权限控制
在main.js全局注册自定义指令,(第一个参数是自定义指令名,第二个参数是inserted回调函数,绑定了该指令的元素被插入到dom上时就会自动执行)通过第二个参数获取其对应的权限点的value属性,然后在vuex中的用户信息里进行筛选看用户是否具有该权限,使用v-if来决定是否显示对应的元素
浏览器底层原理
浏览器是如何解析css选择器的
浏览器是如何进行界面渲染的
浏览器进行界面渲染的过程可以分为以下几个关键步骤:
- 构建 DOM 树:
- 当浏览器接收到 HTML 文件时,它会解析 HTML,并构建 DOM(文档对象模型)树。DOM 树是一个由节点(元素、文本等)构成的层次结构,表示了页面的结构。
- 构建 CSSOM 树:
- 浏览器解析样式表(CSS 文件或内嵌样式),并构建 CSSOM(CSS 对象模型)树。CSSOM 树表示了页面中各个元素的样式信息,包括它们的样式属性和如何相互影响。
- 构建 Render 树:
- DOM 树和 CSSOM 树结合起来构建 Render 树。Render 树是由浏览器用于渲染的树结构,它只包含需要显示的节点和这些节点的样式信息。一些不可见的元素(例如
display: none的元素)不会包含在 Render 树中。
- DOM 树和 CSSOM 树结合起来构建 Render 树。Render 树是由浏览器用于渲染的树结构,它只包含需要显示的节点和这些节点的样式信息。一些不可见的元素(例如
- 布局(Layout):
- 在构建 Render 树后,浏览器进行布局过程,确定每个节点在屏幕上的确切位置和大小。这个过程也称为回流(reflow)。浏览器需要考虑各种因素,如盒模型、文档流、浮动等,来计算元素的准确位置。
- 绘制(Painting):
- 在布局完成后,浏览器进行绘制过程,将页面的内容绘制到屏幕上。这个过程也称为重绘(repaint)。绘制阶段使用绘图引擎将每个元素绘制成像素,考虑元素的颜色、边框、阴影等样式属性。
- 合成(Composite):
- 浏览器将不同层的绘制结果合成在一起,形成最终的页面。现代浏览器通常使用图层来提高页面的性能。图层是一个独立的绘制表面,可以单独绘制和合成,这样在页面更新时只需要重新绘制和合成发生变化的图层,而不是整个页面。
- 渲染刷新:
- 当页面内容发生变化、用户触发交互或浏览器窗口大小改变时,浏览器会重新执行上述渲染流程,以确保页面保持最新。
这个整个渲染过程是一个逐步的、增量的过程。浏览器采用这种方式,以提高页面渲染的性能和用户体验。
前端如何实现实时通讯?
WebSocket(通常缩写为 WS)是一种在单个 TCP 连接上进行全双工通信的协议。与传统的 HTTP 请求-响应模型不同,WebSocket 允许在同一连接上同时进行双向数据传输,实现实时通信。WebSocket 协议最初由 IETF 标准化,目前的标准版本是 RFC 6455。
以下是 WebSocket 的一些重要特性和工作原理:
特性:
- 全双工通信: WebSocket 允许客户端和服务器之间建立持久的连接,实现双向实时通信,而不是像 HTTP 请求-响应那样需要不断地发起新的请求。
- 低延迟: 由于使用了单个 TCP 连接,WebSocket 可以减少因为建立和关闭连接而引入的延迟。
- 轻量级: WebSocket 的协议头较小,通信过程较简单,相对于传统的 HTTP 协议,WebSocket 的开销较小。
- 跨域支持: WebSocket 支持跨域通信,允许在浏览器中进行跨域实时通信。
工作原理:
- 握手阶段: WebSocket 连接的建立始于一个 HTTP 请求,通常称为握手阶段。客户端发起一个 HTTP 请求,请求头中包含协议升级的信息,服务器接受后会响应一个包含握手成功信息的 HTTP 响应。之后,连接协议升级为 WebSocket。
- 数据帧传输: 握手成功后,客户端和服务器之间的通信就进入了数据帧传输阶段。WebSocket 通信使用帧(frame)的概念,每个帧可以携带文本、二进制数据等信息。帧的传输是双向的,客户端和服务器可以同时发送和接收帧。
- 帧格式: WebSocket 帧的格式相对简单,通常包含一个头部和一个数据部分。头部包含帧的类型、长度等信息,数据部分则是实际的传输数据。
- 关闭连接: 当需要关闭连接时,客户端或服务器可以发送一个关闭帧,通知对方关闭连接。收到关闭帧的一方也会发送一个关闭帧,双方最终关闭连接。
JavaScript 中的使用:
在浏览器中,可以使用 JavaScript 的 WebSocket API 来创建 WebSocket 连接。以下是一个简单的示例:
1 | // 创建 WebSocket 连接 |
在这个例子中,onopen、onmessage、onclose 等是 WebSocket 对象的事件处理函数,用于处理连接打开、接收消息、连接关闭等事件。send 方法用于向服务器发送消息。
什么是浏览器同源策略?
同源策略(Same-Origin Policy)是浏览器的一种安全策略,用于限制一个网页文档或脚本如何能够与其他源的资源进行交互。同源策略的核心思想是:不同源的客户端脚本在没有明确授权的情况下,不能读取对方的资源。
同源是指协议(如 http 和 https)、域名和端口号都相同。如果有任何一个不同,就被视为不同源。
同源策略的主要目的是防止恶意网站通过脚本等方式窃取数据,保护用户的隐私和安全。
如何实现跨域获取数据
后端配置cors
前端使用代理转发
JavaScript
说说JavaScript中的数据类型?存储上的差别?
js的数据类型主要分为==基本数据类型==和==引用数据类型==
基本数据类型:7种
1.string
字符串可以使用双引号" "、单引号' '或反引号 ` 标示
1 | let firstName = "John"; |
2.number
3.null
null表示有值但是值为空,可以理解为就是一个毛坯房里面什么东西都没有,通常用来占据位置,未来要往里面赋值
4.undefind
使用let或是var声明了变量但是没有初始化,那么这个变量的值就是undefined
5.boolean
只有两个true和false
6.bigInt(es11新增)
表示任意大的整数类型
普通的整数类型(number)只能安全地存储和运算 -2^53^ -1 到 2^53^-1 这个范围之间的整数,而bigint则没有这个限制。
7.symbol(es6新增)
symbol是一种唯一的、不可变的数据类型,经常用于作为对象属性的键。它的主要特点是每次创建都会生成一个唯一的值,即使使用相同的字符串也无法创建出相同的symbol。
引用数据类型
1.function
是一种特殊类型的对象,可以执行代码块。
2.array
是一种特殊类型的对象,用于按顺序存储多个值。
3.object
用于存储复杂的数据结构,可以包含属性和方法。
js数据类型的检测
1.typeof
typeof操作符用于确定变量或表达式的数据类型,返回一个表示数据类型的字符串。例如:typeof variableName。返回的结果可以是以下字符串之一:"string"、"number"、"boolean"、"undefined"、"object"、"function"、"symbol"或"bigint"。
1 | typeof "Hello" // 返回 "string" |
2.instanceof
instanceof操作符用于检查一个对象是否是某个构造函数的实例。它通常用于检测自定义的对象类型。
1 | var arr = []; |
3.constructor 属性
- 可以使用对象的
constructor属性来检测其构造函数。这通常用于检测自定义对象类型。
1 | var obj = {}; |
4.Object.prototype.toString.call() 方法:
- 这是一种通用的方法,可以用于检测任何数据类型,包括原始数据类型和引用数据类型。
1 | Object.prototype.toString.call("Hello") // 返回 "[object String]" |
5.Array.isArray() 方法:
- 用于检测一个值是否是数组。
1 | Array.isArray([]) // 返回 true |
6.isNaN() 函数:
用于检测一个值是否为 NaN(非数字值)。
1 | isNaN("Hello") // 返回 true |
数组的常用方法有哪些?
操作方法
增
push()方法接收任意数量的参数,并将它们添加到数组末尾,返回数组的最新长度
unshift()在数组开头添加任意多个值,然后返回新的数组长度
splice() 传入三个参数,分别是开始位置、要删除的元素数量、增加的元素,返回一个空数组
删
修改原数组
pop() 方法用于删除数组的最后一项,同时减少数组的length 值,返回被删除的项
shift()方法用于删除数组的第一项,同时减少数组的length 值,返回被删除的项
splice()传入两个参数,分别是开始位置,删除元素的数量,返回包含删除元素的数组
改
查
indexof()返回要查找的元素在数组中的位置,如果没找到则返回 -1
includes()返回要查找的元素在数组中的位置,找到返回true,否则false
find()返回第一个匹配的元素
排序方法
数组翻转reverse()
数组排序sort()方法接受一个比较函数,用于判断哪个值应该排在前面
转换方法
join() 方法接收一个参数,即字符串分隔符,返回包含所有项的字符串
迭代方法
some()对数组每一项都运行传入的测试函数,如果至少有1个元素返回 true ,则这个方法返回 true
every()对数组每一项都运行传入的测试函数,如果所有元素都返回 true ,则这个方法返回 true
forEach()对数组每一项都运行传入的函数,没有返回值
filter()对数组每一项都运行传入的函数,函数返回 true 的项会组成数组之后返回
map()对数组每一项都运行传入的函数,返回由每次函数调用的结果构成的数组
JavaScript字符串的常用方法有哪些?
trim()删除前、后或前后所有空格符,再返回新的字符串
aplit()把字符串按照指定的分割符,拆分成数组中的每一项
== 和 ===区别,分别在什么情况使用
==(相等操作符):
比较过程:
==进行比较时,会进行类型转换,尝试将比较的两个值转换为相同的类型,然后再进行比较。示例:
1
2
3'5' == 5; // true,因为字符串 '5' 会被转换为数字 5
0 == false; // true,因为布尔值 false 会被转换为数字 0
null == undefined; // true,它们被视为相等
===(严格相等操作符):
比较过程:
===进行比较时,不会进行类型转换。只有在两个值的类型和值都相等的情况下,===才会返回true。示例:
1
2
3'5' === 5; // false,因为它们的类型不同
0 === false; // false,因为它们的类型不同
null === undefined; // false,它们的类型相同,但值不同
如何选择使用:
- 推荐使用
===,因为它避免了类型转换带来的一些意外行为,更加严格和可靠。 - 在特定情况下,如果你明确需要进行类型转换,或者想要利用 JavaScript 的隐式类型转换规则,可以使用
==。但需要小心因为类型转换可能导致不直观的结果。 - 一般来说,为了代码的清晰和可读性,最好养成使用
===的习惯,以避免因为隐式类型转换而引起的错误。
深拷贝浅拷贝的区别?如何实现一个深拷贝?
说说你对闭包的理解?闭包使用场景
闭包简单来说就是一个嵌套的函数内层函数能够访问外层函数的局部变量,这个时候就发生了闭包
优点:
- 变量私有化,延长变量的生命周期
缺点
- 变量没有被及时的释放会造成内存泄漏,需要手动进行释放
使用场景
说说你对作用域链的理解
说作用域之前先说一说这个作用域,作用域一般分为三种分别是
块级作用域
在ES6中引入的let和const变量的声明方式具有块级作用域,即在{ }包裹的范围之内都可以被访问到,{ }之外不可以
函数作用域
函数作用域只有在函数内部可以被访问到,外部无法访问
全局作用域
全局作用域下声明的变量是在任何位置都是可以被访问到的
作用域链:
当JavaScript在执行代码访问变量的时候会优先在自身当前作用域查找看有没有,如果没有就会到父级作用域依次逐级向上查找,直到全局作用域,这时如果还是没有找到在非严格模式下会隐式的声明该变量,或者是直接报错
JavaScript原型,原型链 ? 有什么特点?
原型:
每一个构造函数和通过构造函数创建出来的实例对象都有一个共同的原型对象
构造函数是通过prototype属性来访问,实例对象通过__proto__属性来访问原型对象
原型链:
简单来说它可以实现对象之间属性和方法的继承和共享
当一个对象访问其身上的属性和方法的时候,它会优先在自身查找如果没有就会到原型对象身上去查找,如果还没有就会逐级向上到object的原型对象身上查找,直到找到或是到达原型链的末端Object.prototype,这时如果还没有找到就会返回null,这样一个链式查找的过程就叫作原型链
Javascript如何实现继承?
在父类的原型上添加共有的属性或者是方法,使用father.prototype = Object.create(son.prototype)创建了一个新的对象建立起关联
比如说我们创建一个人类person的构造函数,给它添加了一个sayHello的方法
然后我们又创建了一个学生Student的构造函数,给它添加了一个study方法
使用student.prototype = object.create(person.prototype)建立起关联,使其原型链指向person.prototype
这样当我们既可以使用使用学生自身的study方法,也可以使用它原型对象身上的sayHello方法,因为学生自己身上是没有sayHello方法的,就会去原型对象身上去查找,这样就实现了原型的继承
cookie 、localstorage 、 sessionstrorage 之间有什么区别?
大小
cookie,大小大概为4kb左右
而localstorage和sessionstroage的存储空间比cookie要大,大概5m左右
到期时间
cookie可以设置到期时间,在到期时间没过之前一直有效
localstroage将数据永久存储到本地,页面和浏览器关闭后不会丢失
sessionstroage 当浏览器或是页面关闭后存储的数据就会丢失
谈谈this对象的理解
this的指向在不同的函数里面this的指向是不一样的
全局:this指向全局对象也就是window
普通函数:普通函数被当做方法调用的时候指向事件源
箭头函数: 箭头函数的this指向是固定的它会继续沿用上一层作用域中的this指向
构造函数: 构造函数的this指向新创建的实例对象
this指向也是也可以通过 call bind 和apply方法来进行修改的
JavaScript中执行上下文和执行栈是什么?
说说JavaScript中的事件模型
typeof 与 instanceof 区别
typeof 检测基本数据类型
instanceof 检测引用数据类型
用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上
解释下什么是事件代理?应用场景?
说说new操作符具体干了什么?
- 创建一个空的
JavaScript对象。- 一个新的空对象被创建,这个对象被称为构造函数的实例对象。
- 将新对象的
__proto__属性指向构造函数的原型对象。- 每个 JavaScript 函数都有一个特殊的属性称为
prototype,这个属性是一个指向对象的引用。new操作符会将新对象的__proto__属性指向构造函数的prototype属性,这样新对象就可以访问构造函数原型对象上的属性和方法。
- 每个 JavaScript 函数都有一个特殊的属性称为
- 执行构造函数,将新对象绑定到
this。- 构造函数内部的代码被执行,
this关键字指向新创建的对象。这允许构造函数将属性和方法添加到新对象上。
- 构造函数内部的代码被执行,
- 如果构造函数没有显式返回一个对象,那么
new操作符会返回新创建的对象。- 如果构造函数没有使用
return关键字返回一个对象,则new操作符会返回新创建的对象。如果构造函数返回一个对象(不管是显式返回的还是通过构造函数中的代码生成的),则new操作符会返回该对象,而不是新创建的对象。
- 如果构造函数没有使用
ajax原理是什么?如何实现?
bind、call、apply 区别?如何实现一个bind?
call bind apply都是用来改变this的指向
主要有三个方面的修改this指向的时长不一样
call 和 apply 只会改变一次this的指向,并且立即执行
bind,不会立即执行,是返回一个改变this指向之后的一个新的函数
传参方式不一样
call apply是数组列表传参
bind 是 伪数组传参可以分为多传入
说说你对正则表达式的理解?应用场景?
说说你对事件循环的理解
js是一门单线程语言,这就意味这在同一时间只能执行一件任务,遇到异步任务就会造成代码的阻塞
所以js里面所有的任务被分为同步任务和异步任务
代码从上到下执行,会先进入到调用栈执行,遇到异步任务就会交给宿主环境(node.js,浏览器)去执行,执行完成之后放到任务队列中进行排队,接着执行同步任务
等待所有的异步任务执行完毕之后,就会到任务队列中去读取执行,输出结果
异步任务里面又有微任务和宏任务,微任务的优先级比微任务要高,会在任务队列之前插队执行
如此不断循环往复的流程就是事件循环
DOM常见的操作有哪些?
说说你对BOM的理解,常见的BOM对象你了解哪些?
举例说明你对尾递归的理解,有哪些应用场景
说说 JavaScript 中内存泄漏的几种情况?
Javascript本地存储的方式有哪些?区别及应用场景?
说说你对函数式编程的理解?优缺点?
Javascript中如何实现函数缓存?函数缓存有哪些应用场景?
说说 Javascript 数字精度丢失的问题,如何解决?
tofixed()
什么是防抖和节流?有什么区别?如何实现?
一种性能优化手段
防抖:在单位时间内一个事件被多次触发只会执行最后一次
节流:早单位时间内一个事件被多次触发只会执行一次,第二次触发就会重新开始计时,当限制时间过了之后才会执行第二次
实现原理:
防抖
利用settimeout函数开启一个来实现当事件被点击了之后就清除掉原来的定时器重新开启一个新的定时器
1 |
应用场景: 手机号,邮箱的验证,窗口大小resize。只需窗口调整完成后,计算窗口大小。防止重复渲染
节流
在执行settimeout函数之前给他设置一个默认的开关或者是阀门为true,当事件被点击了之后立马把这个变量设置为false,只有在等延时时间过了之后就再次把开关设置为true
1 |
应用场景: html页面滚动的电梯导航,搜索框,搜索联想功能
如何判断一个元素是否在可视区域中?
大文件上传如何做断点续传?
一、是什么
不管怎样简单的需求,在量级达到一定层次时,都会变得异常复杂
文件上传简单,文件变大就复杂
上传大文件时,以下几个变量会影响我们的用户体验
- 服务器处理数据的能力
- 请求超时
- 网络波动
上传时间会变长,高频次文件上传失败,失败后又需要重新上传等等
为了解决上述问题,我们需要对大文件上传单独处理
这里涉及到分片上传及断点续传两个概念
分片上传
分片上传,就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(Part)来进行分片上传
如下图
上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件
大致流程如下:
- 将需要上传的文件按照一定的分割规则,分割成相同大小的数据块;
- 初始化一个分片上传任务,返回本次分片上传唯一标识;
- 按照一定的策略(串行或并行)发送各个分片数据块;
- 发送完成后,服务端根据判断数据上传是否完整,如果完整,则进行数据块合成得到原始文件
断点续传
断点续传指的是在下载或上传时,将下载或上传任务人为的划分为几个部分
每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传下载未完成的部分,而没有必要从头开始上传下载。用户可以节省时间,提高速度
一般实现方式有两种:
- 服务器端返回,告知从哪开始
- 浏览器端自行处理
上传过程中将文件在服务器写为临时文件,等全部写完了(文件上传完),将此临时文件重命名为正式文件即可
如果中途上传中断过,下次上传的时候根据当前临时文件大小,作为在客户端读取文件的偏移量,从此位置继续读取文件数据块,上传到服务器从此偏移量继续写入文件即可
如何实现上拉加载,下拉刷新?
什么是单点登录?如何实现?
web常见的攻击方式有哪些?如何防御?
解释下什么是变量声明提升
变量声明提升是JavaScript中的一种行为,它使得在代码执行前,变量和函数的声明被提升到当前作用域的顶部。这意味着可以在声明之前访问这些变量或函数。
在JavaScript中,有两种声明方式:var关键字和function关键字。对于var声明的变量和使用function声明的函数,它们的声明会被提升。
下面是一个简单的例子,演示了变量声明提升:
1 | console.log(x); // 输出: undefined |
在上面的例子中,虽然console.log(x)在var x = 5之前被调用,但由于变量声明提升,x在该语句执行时已经被声明,只是尚未被赋值,因此输出undefined。而在后续的赋值语句之后,console.log(x)输出了5。
注意,只有声明会被提升,赋值不会。如果一个变量在声明之前被访问,它的值会是undefined。
函数声明也会被提升,例如:
1 | foo(); // 输出: "Hello, World!" |
在上面的例子中,foo()在函数声明之前被调用,但由于函数声明提升,程序会正常输出”Hello, World!”。
需要注意的是,使用let和const关键字声明的变量也有提升,但与var不同,它们在提升阶段不会被初始化,访问时会报错。这被称为”暂时性死区”(Temporal Dead Zone,简称TDZ)。例如:
1 | console.log(x); // 报错:Cannot access 'x' before initialization |
总的来说,变量声明提升是JavaScript语言中的一种特性,了解它有助于避免在代码中出现一些意外的行为。在编写代码时,建议将变量和函数的声明放在当前作用域的顶部,以提高代码的可读性和可维护性。
js的参数是以什么方式进行传递的
js的垃圾回收机制是怎么做的
谈谈你平时都用了哪些方法进行性能优化?
减少http请求次数、打包压缩上线代码、使用懒加载、使用雪碧图、动态渲染组件、CDN加载包。
谈谈你对继承的理解
继承是面向对象编程(OOP)中的一个重要概念,它允许一个对象(子类/派生类)获得另一个对象(父类/基类)的属性和方法。继承是为了实现代码的重用和扩展,使得代码更加模块化、可维护和可扩展。
继承的主要类型:
- 单一继承:
- 一个子类只能继承自一个父类。这是一种简单的继承关系,存在较低的复杂性,但有时可能会限制灵活性。
- 多重继承:
- 一个子类可以同时继承自多个父类。这样可以更灵活地组合不同的功能,但也可能导致复杂性增加,引发一些设计上的问题。
- 多层继承:
- 类型之间形成一个层次结构,子类可以继承自父类,父类又可以继承自更上层的父类。这样的继承关系可以形成一个层次结构。
继承的实现方式:
- 原型链继承:
- 通过将子类的原型设置为父类的实例,从而让子类共享父类的属性和方法。但存在共享引用类型属性的问题,且无法传递参数给父类构造函数。
1 | function Animal() { |
- 构造函数继承(借用构造函数):
- 在子类的构造函数中调用父类的构造函数,通过
call或apply方法来实现。解决了原型链继承的引用类型问题,但无法实现原型链上方法的复用。
- 在子类的构造函数中调用父类的构造函数,通过
1 | function Animal() { |
- 组合继承:
- 结合原型链继承和构造函数继承,既可以共享原型链上的方法,又可以解决构造函数继承的问题。
1 | function Animal() { |
- 原型式继承:
- 利用一个简单的函数创建一个临时构造函数,然后将该构造函数的实例作为子类的原型。ES5 中可以使用
Object.create方法实现。
- 利用一个简单的函数创建一个临时构造函数,然后将该构造函数的实例作为子类的原型。ES5 中可以使用
1 | const animal = { |
- ES6 中的类继承:
- 使用
class关键字定义类,通过extends关键字实现继承。ES6 的类继承更接近传统的面向对象语言的实现方式,语法更简洁。
- 使用
1 | class Animal { |
继承的优缺点:
优点:
- 代码复用: 继承允许子类重用父类的属性和方法,减少代码冗余。
- 扩展性: 可以通过继承来扩展或修改现有类的行为。
缺点:
- 耦合性增加: 高度耦合的继承关系可能导致一个类的改变影响到其他相关的类。
- 可读性下降: 复杂的继承关系可能使代码难以理解和维护。
- 创建对象时的灵活性受限: 子类通常依赖于父类的实现,而不能灵活地改变或替换父类的实现。
如何判断是否为数组
Array.isArray() 方法:
Array.isArray()是最推荐的方法,它是ES5引入的,用于确定传递的值是否是一个数组。返回一个布尔值。
1
2const myArray = [1, 2, 3];
console.log(Array.isArray(myArray)); // trueinstanceof 操作符:
instanceof操作符用于检测构造函数的prototype属性是否出现在对象的原型链中。
1
2const myArray = [1, 2, 3];
console.log(myArray instanceof Array); // true注意:
instanceof可能在涉及多个全局执行上下文的情况下失效,因此在跨框架或跨窗口的环境中不是很可靠。使用 Object.prototype.toString.call() 方法:
Object.prototype.toString.call()方法可以返回一个表示对象的字符串,其中包含了对象的类型信息。对于数组,返回的字符串应该是"[object Array]"。
1
2const myArray = [1, 2, 3];
console.log(Object.prototype.toString.call(myArray) === '[object Array]'); // true
这三种方法中,推荐使用 Array.isArray(),因为它是专门用于检查是否为数组的方法,且更直观。在兼容性较好的环境中,这是最佳选择。如果需要更通用的方法,Object.prototype.toString.call() 也是一种可靠的选择。
Promise的静态方法
调用resolve 结果带到实例方法.then成功的回调里面
reject 结果带到实例方法.catch 失败的回调
race 优先输出第一个异步任务的结果
all 等待所有的异步任务执行完毕之后执行的回调
微任务/宏任务是什么?
async/await是什么?相较于Promise有什么优势
promise的语法糖
解决promise函数调用的回调地狱
async关键字是asynchronous(异步)的简写,用来声明一个函数是异步函数,写在函数的最前面,他会返回一个promise对象
await可以理解为asynchronous wait(等待异步),他会等待一个异步任务返回的结果
下面这两种方法是等效的
1 | function fn() { |
await
正常情况下,await命令后面是一个 Promise 对象,返回该对象的结果。如果不是 Promise 对象,就直接返回对应的值
1 | async function fn(){ |
不管await后面跟着的是什么,await都会阻塞后面的代码
1 | async function fn1 (){ |
上面的例子中,await 会阻塞下面的代码(即加入微任务队列),先执行 async 外面的同步代码,同步代码执行完,再回到 async 函数中,再执行之前阻塞的代码
请写出至少两种常见的数组排序的方法(原生js)
请写至少三种数组去重的方法?(原生js)
知道lodash吗?它有哪些常见的API ?
clone()浅拷贝
clonedeep() 深拷贝
平时都是用那些工具进行打包的?babel是什么?
webpack
对代码进行语法降级,解决兼容性
谈谈Set 、 map 是什么?
Set(集合)
- 定义:
Set是一种值的有序列表,其中的值必须是唯一的,不允许重复。 - 特点:
- 不允许重复的值。
Set中的元素是有序的,插入顺序即为遍历顺序。- 可以包含任意数据类型,包括基本类型和对象引用。
- 常用操作:
add(value): 向集合中添加一个新元素。delete(value): 从集合中删除一个元素。has(value): 判断集合中是否包含某个元素。size: 获取集合中元素的个数。clear(): 清空集合中的所有元素。
Map(映射)
- 定义:
Map是一种键值对的集合,每个键对应一个值。 - 特点:
- 键和值可以是任意数据类型。
- 与对象不同,
Map保留了键的插入顺序。 Map的键是唯一的,每个键只能对应一个值。
- 常用操作:
- ``Set
(key, value): 设置键值对。 get(key): 获取键对应的值。delete(key): 删除键值对。has(key): 判断是否包含某个键。size: 获取 Map 中键值对的个数。clear(): 清空 Map 中的所有键值对。
- ``Set
使用场景:
Set的使用场景:- 去重:利用
Set的唯一性可以轻松实现数组去重。 - 判断值是否存在。
- 去重:利用
1 | const uniqueArray = [...new `Set`([1, 2, 2, 3])]; // [1, 2, 3] |
- Map 的使用场景:
- 存储和查找键值对数据。
- 保持键的顺序。
- 与对象相比,键可以是任意数据类型,不仅限于字符串。
1 | const myMap = new Map(); |
图片懒加载是怎么实现的?
图片的加载是由src引起的,当对src赋值时,浏览器就会请求图片资源。根据这个原理,我们使用HTML5 的data-xxx属性来储存图片的路径,在需要加载图片的时候,将data-xxx中图片的路径赋值给src,这样就实现了图片的按需加载,即懒加载。
注意:data-xxx 中的xxx可以自定义,这里我们使用data-src来定义。
懒加载的实现重点在于确定用户需要加载哪张图片,在浏览器中,可视区域内的资源就是用户需要的资源。所以当图片出现在可视区域时,获取图片的真实地址并赋值给图片即可。
使用原生JavaScript实现懒加载:
知识点:
(1)window.innerHeight 是浏览器可视区的高度
(2)document.body.scrollTop || document.documentElement.scrollTop 是浏览器滚动的过的距离
(3)imgs.offSetTop 是元素顶部距离文档顶部的高度(包括滚动条的距离)
(4)图片加载条件:img.offSetTop < window.innerHeight + document.body.scrollTop;
图示:

for in 和 for of 的区别
for in遍历对象的键也就是属性名,返回的是对应的索引下标
for of 遍历的是可迭代对象的元素也就是值
slice和aplice的区别
slice 方法:
作用:
slice方法用于创建一个新的数组,其中包含从原始数组中选择的元素。
语法:
1
2
array.slice(start, end)参数:
start:开始提取元素的位置(包含该位置的元素)。end:提取元素的结束位置(不包含该位置的元素)。
特点:
- 不修改原始数组,而是返回一个新的数组。
- 如果省略
end参数,slice方法会提取从start位置到数组末尾的所有元素。 - 参数可以是负数,表示从数组末尾开始计数的位置。
splice 方法:
作用:
splice方法用于在数组中添加或删除元素,可以修改原始数组。
语法:
1
2
array.splice(start, deleteCount, item1, item2, ...)参数:
start:开始改变数组的位置。deleteCount:要移除的元素个数(可选,如果设置为 0,则不会删除元素)。item1, item2, ...:要添加到数组的新元素(可选)。
特点:
- 修改原始数组,返回被删除的元素组成的数组。
- 如果
deleteCount为 0,splice可以用于插入新元素。 - 参数可以是负数,表示从数组末尾开始计数的位置。
区别总结:
slice不会改变原始数组,而是返回一个新的数组。splice会改变原始数组,返回被删除的元素组成的数组。slice用于提取数组的一部分,而不影响原数组。splice用于添加、删除或替换数组的元素,并且会直接修改原数组。slice的第二个参数是结束位置(不包含该位置的元素),而splice的第二个参数是要删除的元素个数。splice还可以接受多个参数,用于在指定位置插入新的元素。
substr和substring的区别
substr 方法:
作用:
substr方法用于返回字符串中从指定位置开始的指定长度的子字符串。
语法:
1
string.substr(start, length)
参数:
start:开始提取字符的位置,可以是正整数或负整数。如果是负数,表示从字符串末尾开始计算。length:可选,要提取的字符数。
特点:
- 如果省略
length参数,substr会一直提取到字符串的末尾。 - 如果
start是负数,它将被视为从字符串末尾开始的位置。 - 如果
length是负数或零,它会被视为零。
- 如果省略
substring 方法:
作用:
substring方法用于返回字符串中在两个指定下标之间的子字符串。
语法:
1
2
string.substring(start, end)参数:
start:必须是非负整数,指定子字符串的开始位置。end:可选,必须是非负整数,指定子字符串的结束位置(不包含该位置的字符)。
特点:
- 如果省略
end参数,substring会一直提取到字符串的末尾。 substring不接受负数参数,如果出现负数,会被视为零。- 如果
start大于end,substring会自动交换这两个参数。
- 如果省略
区别总结:
substr的第二个参数是要提取的字符数,而substring的第二个参数是子字符串的结束位置。substr允许使用负数作为起始位置,而substring不接受负数参数。- 如果省略第二个参数,
substr会一直提取到字符串的末尾,而substring也会一直提取到末尾,直到字符串的长度。 - 如果
start大于end,substring会自动交换这两个参数;而对于substr,如果start大于字符串的长度,返回空字符串。
能修改原数组的方法有哪些?
push:
- 在数组末尾添加一个或多个元素,并返回修改后数组的长度。
1
2
3var arr = [1, 2, 3];
arr.push(4, 5);
// arr 现在为 [1, 2, 3, 4, 5]pop:
- 移除数组末尾的元素,并返回被移除的元素。
1
2
3var arr = [1, 2, 3, 4, 5];
var removedElement = arr.pop();
// arr 现在为 [1, 2, 3, 4],removedElement 为 5shift:
- 移除数组的第一个元素,并返回被移除的元素。
1
2
3var arr = [1, 2, 3, 4, 5];
var removedElement = arr.shift();
// arr 现在为 [2, 3, 4, 5],removedElement 为 1unshift:
- 在数组的开头添加一个或多个元素,并返回修改后数组的长度。
1
2
3var arr = [2, 3, 4, 5];
arr.unshift(0, 1);
// arr 现在为 [0, 1, 2, 3, 4, 5]splice:
- 通过删除或替换现有元素或者添加新元素来修改数组。该方法返回被删除的元素组成的数组。
1
2
3var arr = [1, 2, 3, 4, 5];
var removedElements = arr.splice(1, 2, 6, 7);
// arr 现在为 [1, 6, 7, 4, 5],removedElements 为 [2, 3]reverse:
- 颠倒数组中元素的顺序。
1
2
3var arr = [1, 2, 3, 4, 5];
arr.reverse();
// arr 现在为 [5, 4, 3, 2, 1]sort:
- 对数组元素进行排序,可以接受一个比较函数作为参数。
1
2
3var arr = [5, 2, 8, 1, 4];
arr.sort((a, b) => a - b);
// arr 现在为 [1, 2, 4, 5, 8]
说一下你对事件委托的理解
说一说事件的执行过程
中断循环的方式,如何中断forEach
如何判断后台返回的数据是一个空对象
数组、对象解构如何实现
如何二次封装axios
如何进行接口联调
严格模式
promise
promise 是什么?
概念:**Promise** 对象表示异步操作最终的完成(或失败)以及其结果值
这是引用MDN上面的概念,十分的晦涩难懂,简单来说,所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。从语法上说,Promise 是一个对象,它可以获取异步操作的消息
它是ES6新增的语法,主要是为了解决异步函数的层层调用带来的回调地狱问题
promise 的API
静态方法
==resolve==
在异步任务执行成功时会执行,并最终会把结果作为参数带到外面的promise对象实例的.then方法里
==reject==
在异步任务执行失败时会执行,并最终会把结果作为参数带到外面的promise对象实例的.catch方法里*
==all==
并行执行多个异步任务,并且会在所有的异步任务执行完毕之后执行回调,他会接收一个数组异步函数作为参数,它也是会进行异步执行的等上一个任务执行完毕之后才会执行第二个异步任务函数,最终会等数组里面所有的异步任务函数执行完毕后返回一个结果
==race==
.all方法是以谁跑的慢以谁为执行标准,它会等待所有的异步任务执行完毕后,再执行实例对象的.then方法输出结果
而.race方法和.all方法相反,它会看哪一个任务执行完毕了之后,就直接执行了实例对象的.then方法输出结果
实例方法
==then==
==catch==
如何改变 promise 的状态
前面说过promise是一个对象,他会接收一个回调函数作为参数,并且会立即执行
里面的回调函数有两个参数:(由 JavaScript 引擎提供,不用自己部署)
参数1: resolve 函数,将Promise 表示从发送请求时的pending状态变为fullfiled,会在异步操作成功时调用,并将结果作为参数传递出去
参数2: reject 函数, 将Promise 表示从发送请求时的pending状态变为reject,会在异步操作失败时调用,并将结果作为参数传递出去
链式调用: promises/A+规范
手写系列
手写 promise
手写闭包
手写递归
ES6
说说var、let、const之间的区别
var
var声明的变量是全局变量,也就是顶级对象
var声明的变量会进行变量提升,在对代码进行编译的时候会把变量的声明提升到代码最前面,
可以对变量重新赋值,后面的变量会覆盖前面的
函数内声明的变量是局部变量,如果不使用var那么变量就是全局的
let
let声明的变量有块级作用域
无法重复赋值会报错
变量声声明前都是不可用的,也就是暂时性死区
const
只读的一个常量,一旦声明不可以被改变
const声明的变量必须要进行初始化
区别:
1.变量提升
var会进行变量提升,可以在变量在声明之前被调用,值为undefind
let,const不会
2.暂时性死区
var没有暂时性死区
let和const存在暂时性死区,也就是只会在代码执行到变量声明的那一行才可以获取到值
3.块级作用域
var没有块级作用域
let和cost有块级作用域
4.重复声明
var可以重复声明
let和const在同一作用域下不能重复声明
5.变量声明的修改
let和var可以修改声明的变量
const声明的是一个常量,一旦声明不可以被修改,修改会报错
ES6中数组新增了哪些扩展?
ES6中对象新增了哪些扩展?
ES6中函数新增了哪些扩展?
ES6中新增的Set、Map两种数据结构怎么理解?
你是怎么理解ES6中 Promise的?使用场景?
怎么理解ES6中 Generator的?使用场景?
你是怎么理解ES6中Proxy的?使用场景?
你是怎么理解ES6中Module的?使用场景?
你是怎么理解ES6中 Decorator 的?使用场景?
ES6有哪些新特性?
箭头函数:
- 箭头函数提供了更简洁的函数定义语法,并且绑定了词法作用域的 this。
let 和 const:
let和const替代了var,let声明的变量具有块级作用域,const声明常量,其值不可修改。
模板字符串:
- 使用反引号 (``) 定义字符串模板,可以跨行书写,支持变量插值和表达式。
解构赋值:
- 方便地从数组或对象中提取数据,赋值给变量。
默认参数:
- 函数参数可以设置默认值,简化函数的调用。
展开运算符(Spread Operator):
可以在数组、对象等可迭代对象中展开元素,简化数组拼接和对象合并等操作。
…
css
说说你对盒子模型的理解?
css选择器有哪些?优先级?哪些属性可以继承?
CSS选择器用于选择要样式化的HTML元素。以下是一些常见的CSS选择器:
元素选择器:
- 通过元素名称选择元素。例如,
p选择所有段落元素。
1
2
3p {
/* styles */
}- 通过元素名称选择元素。例如,
类选择器:
- 通过类名选择元素。以点(
.)开头,例如,.my-class选择所有具有my-class类的元素。
1
2
3.my-class {
/* styles */
}- 通过类名选择元素。以点(
ID 选择器:
- 通过元素的ID选择元素。以井号(
#)开头,例如#my-id选择具有my-idID 的元素。
1
2
3#my-id {
/* styles */
}- 通过元素的ID选择元素。以井号(
属性选择器:
- 通过元素的属性选择元素。例如,
[type="text"]选择所有type属性为text的元素。
1
2
3[type="text"] {
/* styles */
}- 通过元素的属性选择元素。例如,
后代选择器:
- 选择元素的后代。例如,
ul li选择所有ul元素下的li元素。
1
2
3ul li {
/* styles */
}- 选择元素的后代。例如,
伪类选择器:
- 选择元素的特定状态。例如,
:hover选择鼠标悬停在元素上的状态。
1
2
3a:hover {
/* styles */
}- 选择元素的特定状态。例如,
伪元素选择器:
- 选择元素的特定部分。例如,
::before在元素前添加内容。
1
2
3p::before {
/* styles */
}- 选择元素的特定部分。例如,
优先级
CSS规定了不同选择器的优先级。优先级决定了当多个规则应用到同一元素时,哪个规则的样式将被应用。优先级从高到低依次是:
!important:
- 通过在样式规则中使用
!important标志,可以将其优先级提升到最高。尽量少使用,因为它会增加维护难度。
1
2
3p {
color: red !important;
}- 通过在样式规则中使用
内联样式:
- 使用
style属性直接在元素上定义的样式。
1
<p style="color: blue;">This is a paragraph.</p>
- 使用
ID 选择器:
- 通过ID选择器定义的样式。
1
2
3#my-id {
/* styles */
}类选择器、属性选择器、伪类选择器:
- 类、属性、伪类选择器的优先级相同,按照出现的顺序来决定。
1
2
3
4
5
6
7
8
9
10
11.my-class {
/* styles */
}
[type="text"] {
/* styles */
}
a:hover {
/* styles */
}元素选择器、伪元素选择器:
- 元素选择器和伪元素选择器的优先级相同,按照出现的顺序来决定。
1
2
3
4
5
6
7p {
/* styles */
}
p::before {
/* styles */
}
可继承属性
一些CSS属性可以被子元素继承。这意味着如果父元素具有特定样式,子元素将继承这些样式,除非子元素有自己的样式规则。常见的可继承属性包括:
- 字体相关属性:
font-family、font-size、font-weight等。
- 文本相关属性:
color、line-height、text-align等。
- 列表相关属性:
list-style-type、list-style-image等。
- 表格相关属性:
border-collapse、border-spacing等。
- 链接相关属性:
text-decoration、color(在a标签中)等。
- 生成内容属性:
content(在伪元素中)。
说说em/px/rem/vh/vw区别?
em:
相对单位:
em是相对于其父元素的字体大小的单位。继承性:
em具有继承性,如果一个元素的字体大小是1.5em,那么它将是父元素字体大小的1.5倍。用途: 常用于设置字体大小。
1
2
3
4
5
6
7body {
font-size: 16px;
}
p {
font-size: 1.2em; /* 1.2 * 16px = 19.2px */
}
px:
绝对单位:
px是绝对单位,表示像素。固定大小:
px的大小在不同设备上是固定的。用途: 常用于设置固定大小的元素,如边框、内外边距等。
1
2
3
4div {
border: 1px solid black;
padding: 10px;
}
rem:
相对根元素:
rem是相对于根元素(html)的字体大小的单位。相对一致:
rem的大小相对于根元素,使得在整个页面中保持一致。用途: 用于实现响应式布局,特别是对于整个页面的缩放。
1
2
3
4
5
6
7html {
font-size: 16px;
}
body {
font-size: 1rem; /* 1 * 16px = 16px */
}
vh(视窗高度单位):
相对视窗高度:
vh表示相对于视窗高度的百分比。相对一致: 1vh 等于视窗高度的1%。
用途: 常用于制作具有视窗高度相关布局的元素。
1
2
3div {
height: 50vh; /* 视窗高度的50% */
}
vw(视窗宽度单位):
相对视窗宽度:
vw表示相对于视窗宽度的百分比。相对一致: 1vw 等于视窗宽度的1%。
用途: 常用于制作具有视窗宽度相关布局的元素。
1
2
3div {
width: 25vw; /* 视窗宽度的25% */
}
区别总结:
- em: 相对于父元素的字体大小。
- px: 绝对单位,固定大小。
- rem: 相对于根元素的字体大小,用于实现整体页面的缩放。
- vh: 相对于视窗高度的百分比,用于视窗高度相关布局。
- vw: 相对于视窗宽度的百分比,用于视窗宽度相关布局。
说说设备像素、css像素、设备独立像素、dpr、ppi 之间的区别?
谈谈你对BFC的理解?
BFC,即块级格式化上下文(Block Formatting Context),是CSS中一个重要的概念。BFC是页面上的一个独立的渲染区域,规定了内部的块级盒子如何布局,并且与这个区域外部毫不相干。
BFC的特性:
- 块级盒子: BFC内部的所有元素都是块级盒子,这意味着它们按照块级盒子的标准布局。
- 上下文独立: BFC内部的元素不会影响到外部元素,反之亦然。这意味着BFC内外的布局互不影响,使得页面布局更加灵活。
- 阻止外边距重叠: 在同一个BFC中,相邻块级元素的外边距不会发生重叠。
- 包含浮动: BFC会包含其内部的浮动元素,使得父元素可以自适应其内部浮动元素的高度。
- 阻止文字环绕: BFC可以阻止文字环绕浮动元素,使得文字不会环绕在浮动元素的周围。
创建BFC的条件:
- 根元素: 页面的根元素(
<html>)即为一个BFC。 - 浮动元素: 元素的
float属性不为none。 - 绝对定位元素: 元素的
position属性为absolute或fixed。 - 行内块元素: 元素的
display属性为inline-block。 - 表格单元格元素: 元素的
display属性为table-cell。 - 弹性盒子(Flex container): 元素的
display属性为flex或inline-flex。 - 网格布局容器(Grid container): 元素的
display属性为grid或inline-grid。
BFC的应用场景:
清除浮动: 使用BFC可以清除浮动,避免父元素塌陷。
1
2
3
4
5.clearfix::after {
content: "";
display: table;
clear: both;
}防止外边距重叠: 在需要阻止外边距重叠的情况下,可以使用BFC。
自适应两栏布局: 通过将父元素设为BFC,可以包含内部浮动元素,实现自适应两栏布局。
阻止文字环绕: 在需要阻止文字环绕浮动元素的情况下,可以使用BFC。
元素水平垂直居中的方法有哪些?如果元素不定宽高呢?
元素水平垂直居中的方法:
使用Flexbox:
- 对于容器,设置
display: flex;和justify-content: center; align-items: center;。
1
2
3
4
5.container {
display: flex;
justify-content: center;
align-items: center;
}- 对于容器,设置
使用Grid布局:
- 对于容器,设置
display: grid;和place-items: center;。
1
2
3
4.container {
display: grid;
place-items: center;
}- 对于容器,设置
使用绝对定位和负边距:
- 对于需要居中的元素,设置
position: absolute;,然后通过负边距和top,left,bottom,right组合实现居中。
1
2
3
4
5
6.centered {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}- 对于需要居中的元素,设置
使用表格布局:
- 对于容器,设置
display: table;,然后对子元素设置display: table-cell; vertical-align: middle; text-align: center;。
1
2
3
4
5
6
7
8
9.container {
display: table;
}
.centered {
display: table-cell;
vertical-align: middle;
text-align: center;
}- 对于容器,设置
元素不定宽高的水平垂直居中:
使用Flexbox和margin: auto:
- 对于容器,设置
display: flex;和justify-content: center; align-items: center;,然后对子元素设置margin: auto;。
1
2
3
4
5
6
7
8
9.container {
display: flex;
justify-content: center;
align-items: center;
}
.centered {
margin: auto;
}- 对于容器,设置
使用绝对定位和transform:
- 对于需要居中的元素,设置
position: absolute;和transform: translate(-50%, -50%);。
1
2
3
4
5
6.centered {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}- 对于需要居中的元素,设置
使用Flexbox和百分比定位:
- 对于容器,设置
display: flex;和justify-content: center; align-items: center;,然后对子元素设置position: relative;和top: 50%; left: 50%; transform: translate(-50%, -50%);。
1
2
3
4
5
6
7
8
9
10
11
12.container {
display: flex;
justify-content: center;
align-items: center;
}
.centered {
position: relative;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}- 对于容器,设置
如何实现两栏布局,右侧自适应?三栏布局中间自适应呢?
两栏布局,右侧自适应:
1 |
|
三栏布局,中间自适应:
1 |
|
说说flexbox(弹性盒布局模型),以及适用场景?
介绍一下grid网格布局
CSS3新增了哪些新特性?
1.颜色:rgba和hsla模式
1 | background-color: rgba(255,255,255,0.5) //白色半透明 |
HSL和HSLA颜色:HSL代表色相、饱和度和亮度,而HSLA添加了Alpha通道。这种颜色表示方法更直观,允许你在颜色的基础上进行更精确的调整。例如:
1 | background-color: hsl(120, 100%, 50%); /* 设置绿色背景 */ |
2.文字阴影text-shadow
3.边框圆角border-radius,盒子阴影box-shadow
4.盒子模型 box-sizing
5.字体图标 iconfont
6.弹性布局 flex
css3动画有哪些?
怎么理解回流跟重绘?什么场景下会触发?
回流(Reflow):
- 定义: 回流是浏览器为了重新渲染部分或全部页面而重新计算元素的位置和几何结构的过程。
- 触发场景: 回流会在以下情况下触发:
- 添加或删除可见的DOM元素。
- 元素位置发生变化。
- 元素的尺寸发生变化(包括边距、填充、边框、宽度和高度变化)。
- 浏览器窗口尺寸发生变化。
- 影响: 回流是一种代价高昂的操作,会触发布局的重新计算,影响整个页面的渲染性能。
重绘(Repaint):
- 定义: 重绘是当元素样式发生改变,但不影响其布局时,浏览器将之前绘制的内容重新绘制的过程。
- 触发场景: 重绘会在以下情况下触发:
- 修改元素的颜色。
- 修改元素的背景。
- 修改元素的可见性。
- 修改元素的轮廓(边框)。
- 影响: 重绘的性能开销相对较小,因为它不会影响元素的布局,只需重新绘制颜色等样式信息。
优化建议:
- 避免直接操作样式: 使用
classList等方法修改类名,一次性更改样式,减少回流和重绘的次数。 - 使用文档片段: 对多次 DOM 操作,可以使用文档片段(DocumentFragment)来减少回流。
- 离线操作: 在对 DOM 进行复杂操作时,可以将元素脱离文档流,完成操作后再放回文档流。
- 使用定时器: 对于某些频繁触发的操作,可以使用定时器将其延迟执行,合并多次操作。
- 优化动画: 对于频繁发生的动画,使用
transform和opacity等属性进行优化,避免影响布局。
什么是响应式设计?响应式设计的基本原理是什么?如何做?
如果要做优化,CSS提高性能的方法有哪些?
如何实现单行/多行文本溢出的省略样式?
如何使用css完成视差滚动效果?
CSS如何画一个三角形?原理是什么?
让Chrome支持小于12px 的文字方式有哪些?区别?
说说对Css预编语言的理解?有哪些区别?
在css中有哪些定位方式
- Static(静态定位):
position: static;- 默认值,元素在正常文档流中定位,不受 top, right, bottom, left 属性的影响。
- Relative(相对定位):
position: relative;- 相对于元素在正常文档流中的位置进行定位。通过设置 top, right, bottom, left 属性可以使元素相对于其正常位置进行移动。
- Absolute(绝对定位):
position: absolute;- 相对于最近的已定位祖先元素(不包括 static 定位的元素),如果没有已定位的祖先元素,则相对于最初的包含块(通常是
<html>元素)进行定位。
- Fixed(固定定位):
position: fixed;- 相对于浏览器窗口进行定位,即使页面滚动,元素位置也不会改变。
- Sticky(粘性定位):
position: sticky;- 相对于用户滚动的容器(滚动时相对于视窗,不滚动时相对于最近的块级祖先)进行定位。在容器滚动到某个阈值之前,元素为相对定位;之后,元素为固定定位。
如何理解z-index?
如何画一个0.5像素的线
1. 使用半透明颜色:
1 | .line { |
这样的话,线条看起来会比较淡,模拟出0.5像素的效果。
2. 使用box-shadow:
1 | .line { |
这种方式利用 box-shadow 的模糊效果来实现,同样也可以模拟出较细的线条。
如何清除浮动?
你对媒体查询的理解
标准盒模型和怪异盒模型有哪些区别?
伪类和伪元素的区别
http
什么是HTTP? HTTP 和 HTTPS 的区别?
在回答这个问题时,你可以提供以下基本信息:
- HTTP(Hypertext Transfer Protocol):HTTP(超文本传输协议):
- HTTP是一种用于在Web上进行数据传输的协议。
- 它基于客户端-服务器模型,客户端发送请求,服务器返回响应。
- HTTPS(Hypertext Transfer Protocol Secure):HTTPS(安全超文本传输协议):
- HTTPS是HTTP的安全版本,通过加密通信内容来提高安全性。
- 它使用SSL(Secure Sockets Layer)或TLS(Transport Layer Security)协议来保护数据传输的安全性。
- 区别:
- 安全性: HTTP是明文传输的,数据不加密,容易被中间人攻击。而HTTPS通过加密通信内容,确保数据的保密性和完整性,防止窃听和篡改。
- 协议: HTTP使用标准的HTTP协议,而HTTPS在HTTP的基础上加入了SSL或TLS协议,通过这两种协议进行数据加密。
- 端口: HTTP默认使用端口80,而HTTPS默认使用端口443。
- 证书: 在使用HTTPS时,服务器需要获得一个数字证书,由可信任的证书颁发机构(CA)签发,用于验证服务器身份。而HTTP通信过程中无法验证服务器的真实性。
为什么说HTTPS比HTTP安全? HTTPS是如何保证安全的?
- 加密传输: HTTPS使用SSL(Secure Sockets Layer)或TLS(Transport Layer Security)协议对数据进行加密。这意味着在数据传输过程中,即使被截获,也难以被解读,因为只有具备解密密钥的接收方才能还原原始数据。这有助于防止窃听和数据篡改攻击。
- 身份验证: 使用HTTPS的服务器需要获得数字证书,由可信任的证书颁发机构(CA)签发。这个证书用于验证服务器的身份。这种机制有助于防止中间人攻击,确保用户与服务器之间的通信是与正确的服务器建立的连接。
- 数据完整性: 在HTTPS通信中,数据的完整性得到了保护,因为SSL/TLS协议使用哈希函数对传输的数据进行摘要,确保数据在传输过程中没有被篡改或损坏。
- 防范混合内容攻击: HTTPS可以防止混合内容攻击,即阻止非安全来源(HTTP)的内容与安全来源(HTTPS)的内容混合在同一个页面上,提高了整体安全性。
如何理解UDP 和 TCP? 区别? 应用场景?
- 理解 UDP 和 TCP:
- UDP(User Datagram Protocol):UDP(用户数据报协议):
- UDP是一种无连接的协议,它不提供像TCP那样的可靠性和顺序传输。
- UDP通过数据包(Datagram)的方式发送数据,每个数据包都是一个独立的实体,相互之间没有关联。
- UDP不保证数据的可靠性和顺序性,但由于其简单性和低开销,适用于一些实时性要求较高的应用场景。
- TCP(Transmission Control Protocol):TCP(传输控制协议):
- TCP是一种面向连接的协议,提供可靠的、有序的数据传输服务。
- TCP通过建立连接、数据传输和断开连接的三个阶段来确保数据的完整性和有序性。
- TCP使用流(Stream)的方式传输数据,数据被划分为小的数据块,并确保它们按照顺序传送到目标。
- UDP(User Datagram Protocol):UDP(用户数据报协议):
- 区别:
- 可靠性:
- UDP是不可靠的,不保证数据的可靠性和顺序性。
- TCP是可靠的,通过确认机制和重传机制确保数据的可靠传输。
- 连接性:
- UDP是无连接的,每个数据包独立处理,相互之间没有关联。
- TCP是面向连接的,通过建立连接来确保数据传输的完整性。
- 开销:
- UDP的开销相对较低,适用于对实时性要求较高的场景。
- TCP的开销较大,但能够提供可靠的、有序的数据传输。
- 可靠性:
- 应用场景:
- UDP:
- 适用于实时性要求较高、可以容忍少量数据丢失的场景,如音频和视频流的传输、在线游戏等。
- 由于UDP的简单性和低开销,也常用于广播和多播通信。
- TCP:传输控制协议:
- 适用于对数据完整性和有序性要求较高的场景,如文件传输、Web页面加载、电子邮件等。
- 在需要确保每个数据包都能被正确接收的情况下,使用TCP更为合适。
- UDP:
如何理解OSI七层模型?
- OSI 七层模型概述:
- OSI七层模型是国际标准化组织(ISO)定义的网络体系结构模型,用于指导不同厂商的网络设备和协议的开发。
- 它将网络通信划分为七个逻辑层次,每个层次负责特定的功能,每个层次的功能都建立在下一层提供的服务之上。
- 七个层次及其功能:
- 物理层(Physical Layer):
- 主要关注数据的物理传输,例如电缆、光纤、物理连接等。
- 定义了数据的传输速率、电压等物理特性。
- 数据链路层(Data Link Layer):
- 提供了可靠的点对点和点对多点通信。
- 通过帧(Frame)定义数据的格式,进行错误检测和纠正。
- 网络层(Network Layer):
- 负责数据的路由和寻址,实现不同网络之间的通信。
- 使用IP地址标识网络上的设备,进行数据包的转发。
- 传输层(Transport Layer):
- 提供端到端的通信服务,确保数据的可靠传输。
- 通过TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)实现数据的流控制和错误处理。
- 会话层(Session Layer):
- 管理不同设备之间的通信会话,确保数据的有序传输。
- 提供建立、维护和关闭会话的功能。
- 表示层(Presentation Layer):
- 负责数据的格式转换、加密和解密,确保数据的格式一致性。
- 处理数据的语法和语义问题。
- 应用层(Application Layer):
- 提供网络服务和应用程序之间的接口。
- 包括用户界面、网络协议和各种应用。
- 物理层(Physical Layer):
- 理解七层模型的好处:
- 模块化设计: 每个层次都有特定的功能,使得网络设计更具模块化和可扩展性。
- 标准化: 每个层次的功能都有明确定义的标准,促使了不同厂商设备和协议的互操作性。
- 问题定位: 当网络出现问题时,七层模型有助于迅速定位问题所在的层次。
如何理解TCP/IP协议?
- TCP/IP协议概述:
- TCP/IP是一组用于互联网通信的协议,包括Transmission Control Protocol (TCP) 和 Internet Protocol (IP)。
- 它是互联网的基础通信协议,被用于在网络中传输数据。
- TCP 和 IP 的角色:
- TCP(Transmission Control Protocol):TCP(传输控制协议):
- 提供可靠的、面向连接的通信服务。
- 确保数据的可靠性、有序性和完整性,通过确认机制和重传机制实现。
- IP(Internet Protocol):IP(互联网协议):
- 负责数据包的寻址和路由。
- 定义了数据包在网络中的传输方式,通过IP地址标识设备和网络。
- TCP(Transmission Control Protocol):TCP(传输控制协议):
- TCP/IP协议族:
- TCP/IP协议族包含多个协议,不仅限于TCP和IP,还包括一系列支持网络通信的协议,如UDP、ICMP、ARP等。
- 分层结构:
- TCP/IP协议以分层结构组织,分为四个层次,分别是应用层、传输层、网络层和数据链路层。
- 这种分层结构有助于实现模块化设计和互操作性。
- 应用场景:
- TCP/IP协议被广泛应用于互联网,支持各种应用,包括Web浏览、电子邮件、文件传输等。
- 它也是局域网(LAN)和广域网(WAN)中常用的协议。
- 开放标准:
- TCP/IP是一个开放标准,使得不同厂商的设备和软件可以互相通信,促进了互联网的发展和扩展。
DNS协议 是什么?说说DNS 完整的查询过程?
DNS(Domain Name System)是一种用于将域名(例如www.example.com)转换为对应IP地址的分布式命名系统。它是互联网中用于解析域名的一种关键服务。
DNS查询过程涉及多个步骤,以下是DNS完整的查询过程:
- 本地缓存查询:
- 首先,计算机会检查本地缓存,查看之前解析过的域名是否存在于缓存中。如果存在,且尚未过期,就直接使用缓存中的IP地址,从而避免了向DNS服务器发送请求。
- 递归查询:
- 如果本地缓存中没有相应的记录,计算机将向本地DNS服务器发起递归查询。本地DNS服务器通常由Internet服务提供商(ISP)或其他网络服务提供商提供。
- 本地DNS服务器查询根域名服务器:
- 如果本地DNS服务器无法解析域名,它将向根域名服务器发送查询请求。根域名服务器是全球DNS体系结构的起始点,负责指导DNS查询进入正确的顶级域名服务器。
- 根域名服务器返回顶级域名服务器地址:
- 根域名服务器收到请求后,返回顶级域名服务器的地址。顶级域名服务器负责管理特定顶级域(如.com、.org)下的域名信息。
- 本地DNS服务器查询顶级域名服务器:
- 本地DNS服务器向顶级域名服务器发起查询请求,请求该域名对应的下一级域名服务器的地址。
- 顶级域名服务器返回权威域名服务器地址:
- 顶级域名服务器返回包含权威域名服务器地址的响应。权威域名服务器是负责管理特定域的具体域名解析信息的服务器。
- 本地DNS服务器查询权威域名服务器:
- 本地DNS服务器向权威域名服务器发起查询请求,请求解析特定域名的IP地址。
- 权威域名服务器返回解析结果:
- 权威域名服务器返回包含目标域名的IP地址的响应给本地DNS服务器。
- 本地DNS服务器缓存结果:
- 本地DNS服务器将从权威域名服务器获取的IP地址存储在缓存中,以备将来使用,并将解析结果返回给计算机。
- 计算机使用IP地址访问目标网站:
- 最后,计算机获得了域名对应的IP地址,并可以使用该IP地址与目标服务器建立连接,实现数据传输。
如何理解CDN?说说实现原理?
CDN(Content Delivery Network)是一种用于提高网络性能、减少加载时间以及增强网站安全性的分布式服务。CDN的主要目标是通过在全球范围内部署多个服务器节点,将网站的静态资源(如图像、样式表、脚本等)缓存到这些节点上,从而使用户可以从离他们更近的服务器获取这些资源,提高访问速度和用户体验。
CDN的实现原理包括以下关键步骤:
- 内容缓存和分发:
- CDN提供商将网站的静态内容(如图片、视频、CSS、JavaScript等)复制到位于全球各地的多个服务器节点上。这些节点通常分布在不同的地理位置,覆盖各个大洲和国家。
- DNS解析优化:
- 当用户发起访问请求时,CDN通过DNS解析确定用户的地理位置,并将用户的请求引导到离用户最近的CDN服务器。这通过将域名映射到最近的CDN服务器IP地址来实现。
- 请求处理和内容提供:
- 用户的请求被发送到最近的CDN服务器,该服务器检查是否已缓存所请求的内容。如果缓存中存在,则直接返回缓存的内容;如果不存在,则向源服务器请求内容,并将内容缓存起来,供将来的请求使用。
- 动态内容优化:
- 对于动态内容(如个性化的用户数据、动态生成的页面等),CDN提供商可能使用一些技术,如边缘计算(Edge Computing)或者将请求转发到源服务器。这确保了即使是动态生成的内容也能在用户附近快速响应。
- 负载均衡:
- CDN使用负载均衡算法来分配用户请求到不同的服务器节点,以确保每个节点都能平均处理请求负荷,提高整体的性能和可靠性。
- 安全性增强:
- CDN通常提供安全功能,如DDoS攻击防护、SSL加密等,以增强网站的安全性。
- 实时监控和分析:
- CDN提供商通常通过实时监控和分析来了解网络状况,根据流量负载和性能指标动态调整服务器节点的分发策略,以最优化内容传递。
说说 HTTP1.0/1.1/2.0 的区别?
- HTTP 1.0:
- 连接管理: 使用短连接(short-lived connections),每个请求/响应都需要建立一个新的TCP连接。这导致了高延迟和性能低效。
- 性能: 每个请求只能得到一个响应,不能复用连接,导致性能相对较差。
- 无状态: HTTP 1.0是无状态的,每个请求都是独立的,服务器不会保留任何关于客户端状态的信息。
- HTTP 1.1:
- 持久连接: 引入了持久连接(persistent connections),允许在单个TCP连接上发送多个请求和响应,减少了连接建立的开销。
- 管道化: 支持请求/响应的管道化,可以在一个连接上同时发送多个请求,但由于实现的复杂性和一些潜在的问题,该特性并没有被广泛采用。
- 分块传输编码: 支持分块传输编码(chunked transfer encoding),允许服务器逐块发送响应,而不需要等到整个响应生成完成。
- HTTP 2.0:
- 多路复用: 最显著的改变是引入了多路复用(multiplexing),允许在单个连接上同时发送多个请求和响应,解决了头阻塞问题,提高了性能。
- 二进制协议: 使用二进制格式替代了文本格式,提高了解析的效率。
- 头部压缩: 引入了头部压缩(header compression),减小了传输的开销。
- 服务器推送: 支持服务器推送,服务器可以在客户端请求之前将额外的资源推送给客户端,提高性能。
说说 HTTP 常见的状态码有哪些,适用场景?
200 表示请求成功
301访问地址永久重定向
302 临时重定向
400-499 客户端错误
401 表示未授权
403 表示禁止访问,没有权限
404 表示请求地址错误,没有对应的资源文件
500 表示服务端错误
说一下 GET 和 POST 的区别?
- 用途:
- GET: 主要用于请求获取资源,参数通常附加在URL的末尾,通过查询字符串传递。GET请求应该是幂等的,即多次请求的结果应该是一致的,不应该有副作用。
- POST: 主要用于向服务器提交数据,通常通过请求体传递参数。POST请求可以用于更新服务器上的资源,可能有副作用,不一定是幂等的。
- 数据传输方式:
- GET: 数据通过URL的查询字符串传递,可见于URL中,有长度限制。适合传递少量的非敏感数据。
- POST: 数据传递在请求体中,对传输的数据类型没有限制,可以传递大量数据,更安全,因为数据不会出现在URL中。
- 安全性:
- GET: 因为数据在URL中可见,不适合传递敏感信息,例如密码等。GET请求更容易被缓存,被浏览器记录,不适合用于传输敏感信息。
- POST: 数据传递在请求体中,相对于GET更安全,适合用于传输敏感信息,如登录凭据。
- 可缓存性:
- GET: 请求结果容易被缓存,可以被浏览器添加到浏览器历史记录。
- POST: 请求结果不容易被缓存,不会被浏览器添加到浏览器历史记录。
- 幂等性:
- GET: 应该是幂等的,多次请求的结果应该是一致的。
- POST: 不要求幂等性,多次请求可能导致不同的结果。
说说 HTTP 常见的请求头有哪些? 作用?
- Host:
- 作用: 指定服务器的域名和端口号,告诉服务器请求的目标是哪个主机。
- 示例:
Host: www.example.com
- User-Agent:
- 作用: 标识客户端的类型和版本,帮助服务器了解请求的来源。
- 示例:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3
- Accept:
- 作用: 告诉服务器客户端能够处理哪些类型的响应数据,通常是指MIME类型。
- 示例:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
- Accept-Language:
- 作用: 指定客户端能够接受的语言类型,用于服务器选择合适的语言返回响应。
- 示例:
Accept-Language: en-US,en;q=0.5
- Accept-Encoding:
- 作用: 指定客户端支持的内容编码方式,服务器可以使用这些编码来压缩响应数据。
- 示例:
Accept-Encoding: gzip, deflate
- Connection:
- 作用: 控制是否需要持久连接,或者在请求完成后关闭连接。
- 示例:
Connection: keep-alive
- Referer:
- 作用: 表示请求的来源,即当前请求是从哪个URL过来的。
- 示例:
Referer: http://www.example.com/page
- Cookie:
- 作用: 包含客户端的Cookie信息,用于在请求中传递会话信息等状态。
- 示例:
Cookie: username=johndoe; sessionid=abc123
- Authorization:
- 作用: 包含了用于进行身份验证的凭证信息,例如用户名和密码。
- 示例:
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
- Content-Type:
- 作用: 指定请求体的媒体类型,用于告诉服务器发送的数据的格式。
- 示例:
Content-Type: application/json
说说地址栏输入 URL 敲下回车后发生了什么?
当在浏览器地址栏输入URL并按下回车时,发生的过程可以简要概括为以下几个步骤:
- URL解析:
- 浏览器首先对输入的URL进行解析,提取出协议、主机名、端口号、路径和查询参数等信息。
- DNS解析:
- 浏览器通过DNS(Domain Name System)解析获取服务器的IP地址,以便建立TCP连接。如果浏览器缓存中没有对应的IP地址,将发起DNS查询请求。
- 建立TCP连接:
- 浏览器通过使用HTTP或HTTPS等协议,与服务器建立TCP连接。对于HTTPS,还需要进行SSL/TLS握手过程建立安全连接。
- 发起HTTP请求:
- 浏览器向服务器发送HTTP请求,包括请求方法(GET、POST等)、路径、请求头、可能的请求体等信息。
- 服务器处理请求:
- 服务器接收到请求后,根据路径和其他信息,处理相应的业务逻辑,可能涉及到数据库查询、动态页面生成等。
- 服务器发送HTTP响应:
- 服务器生成HTTP响应,包括状态码、响应头、响应体等,并将其发送回给浏览器。
- 浏览器接收响应:
- 浏览器接收到服务器的响应后,根据响应头中的信息判断如何处理响应,可能包括渲染HTML、执行JavaScript、加载资源等。
- 渲染页面:
- 如果响应是HTML,浏览器开始解析HTML文档,构建DOM树;同时,解析CSS创建样式规则,构建CSSOM树;最终,将DOM树和CSSOM树结合,生成渲染树,然后进行布局和绘制,最终将页面显示在用户界面上。
- 执行JavaScript:
- 如果HTML中包含了JavaScript,浏览器会执行相应的JavaScript代码,可能导致对DOM的修改、发起新的网络请求等操作。
- 加载资源:
- 页面可能包含引用的其他资源,如图片、样式表、脚本文件等,浏览器会根据需要加载这些资源。
整个过程中,浏览器和服务器之间的通信主要依赖于HTTP协议,而浏览器通过解析HTML、执行JavaScript等来呈现最终的用户界面。这一系列的步骤被称为“HTTP请求-响应周期”或“浏览器渲染流程”。
说说TCP为什么需要三次握手和四次挥手?
TCP(Transmission Control Protocol)是一种面向连接的协议,为了确保可靠的数据传输,建立和终止连接时采用了三次握手和四次挥手的过程。
三次握手(Three-Way Handshake):
- 第一次握手(SYN):
- 客户端发送一个TCP报文,其中标志位SYN(同步序列编号)被置为1,同时选择一个初始序列号(ISN)。
- 第二次握手(SYN + ACK):
- 服务器收到客户端的SYN报文后,会回复一个带有SYN和ACK标志位的报文,表示同意建立连接,并同时选择自己的初始序列号。
- 第三次握手(ACK):
- 客户端收到服务器的SYN + ACK报文后,向服务器发送一个带有ACK标志位的报文,表示握手过程完成。
原因:
- 第一次握手:建立连接时,客户端告诉服务器自己要发送数据了。
- 第二次握手:服务器收到客户端的请求,准备好并告诉客户端可以发送数据了。
- 第三次握手:客户端收到服务器的同意,此时连接建立,双方可以开始进行数据传输。
四次挥手(Four-Way Handshake):
- 第一次挥手(FIN):
- 客户端发送一个TCP报文,其中标志位FIN(终止连接)被置为1,表示客户端没有数据要发送了。
- 第二次挥手(ACK):
- 服务器收到客户端的FIN报文后,向客户端发送一个带有ACK标志位的报文,表示已经收到了客户端的关闭请求。
- 第三次挥手(FIN):
- 服务器关闭与客户端的连接,发送一个带有FIN标志位的报文,告知客户端服务器也准备好关闭连接。
- 第四次挥手(ACK):
- 客户端收到服务器的FIN报文后,向服务器发送一个带有ACK标志位的报文,表示已经收到了服务器的关闭请求。
原因:
- 第一次挥手:客户端没有数据要发送了,告诉服务器可以关闭连接。
- 第二次挥手:服务器收到客户端的关闭请求,告诉客户端自己也准备好关闭连接。
- 第三次挥手:服务器关闭连接,告知客户端可以安全关闭了。
- 第四次挥手:客户端收到服务器的关闭请求,向服务器发送确认,完成关闭过程。
这样的设计可以确保在连接的建立和断开过程中,双方都能够明确地知道彼此的状态,从而确保数据的可靠传输和连接的正确关闭。
说说对WebSocket的理解?应用场景?
WebSocket是一种在单个TCP连接上提供全双工通信的协议,它允许在客户端和服务器之间进行实时、双向的数据传输。WebSocket协议相对于传统的HTTP通信有更低的延迟和更小的开销,因为它避免了在每次通信时都建立新的连接。
WebSocket的特点和工作原理:
- 全双工通信: WebSocket允许客户端和服务器之间双向实时通信,可以同时发送和接收数据,而不需要等待对方的响应。
- 持久连接: WebSocket连接一旦建立,可以保持持久性,不需要重复的握手和断开。
- 低延迟: 相对于传统的HTTP轮询或长轮询,WebSocket可以实现更低的延迟,因为通信是即时的,而不需要等待定时轮询。
- 轻量级: 与HTTP相比,WebSocket协议的头部开销较小,减少了通信的数据量。
WebSocket的工作过程:
- 握手阶段:
- 客户端发起WebSocket连接请求,请求中包含Upgrade头,服务器返回101状态码表示同意升级协议,之后WebSocket连接建立。
- 数据传输阶段:
- 客户端和服务器可以通过WebSocket连接进行双向的实时数据传输,可以同时发送和接收消息。
- 关闭阶段:
- 要关闭连接,一方发送一个带有关闭标志的数据帧,另一方接收到后也发送一个带有关闭标志的数据帧,连接就被关闭。
应用场景:
- 即时通讯: WebSocket适用于实时通讯应用,如在线聊天、消息推送等,因为它允许双方实时发送消息而无需不断建立新的连接。
- 在线游戏: 在线游戏通常需要实时的双向通信,WebSocket可以提供低延迟和高效的数据传输。
- 实时协作: 在协作应用中,多个用户可以实时地编辑和查看共享的文档或画布,WebSocket可以用于同步用户的操作。
- 金融交易: 在金融领域,实时性是非常重要的,WebSocket可以用于实时更新股票价格、交易信息等。
- 实时监控: WebSocket可以用于实时监控系统,及时推送监控数据和报警信息。
总体而言,WebSocket适用于需要实时、双向通信的场景,它提供了更为高效和低延迟的解决方案,相对于传统的HTTP通信在某些应用场景中具有明显的优势。
小程序
说说你对微信小程序的理解?优缺点?
体积小,无需安装,直接在微信里面使用方便用户
小程序里面怎么发请求?
这个是最麻烦的,微信小程序原生有wx.request使用回调函数的方式发请求,不支持promise,更没有axios,所以写起来比较麻烦,
- 我之前在原生开发的时候下载了一个第三方包,包名好像叫
wx_network,wechat_http,有点忘记了,可以支持promise,支持写请求和响应拦截器等,好用 - 在uni-app里面开发的时候,使用的是
uni.request,这个方法被uni-app自己封装为了promise的版本,但是返回值是一个数组的形式,const [err, res] = await uni.request('xxxx'),也不是很好用 - 最后,我在上份工作里面,用的是
uview-ui组件库, 这个框架除了给我们提供了组件以外,还给全局的uni绑定了一些 优化请求的方式,uni.$u.http。 我们就可以配置请求的基地址 ,请求响应拦截器。 后面的工作一直用的是它
小程序有跨域吗?
没有,只有浏览器有跨域的说法,服务器和小程序都没有跨域,跨域是浏览器这个软件的安全策略
- 小程序开发的时候: 在开发者工具勾选一个不校验
http的选项就可以了、 - 上线以后怎么办: 小程序的后台网站,开发设置里面配置一下对应的域名,好像可以添加200个
小程序常见的组件通信方式
- 父子通信:类似于vue,父向子
properties,子向父通信triggerEvent - 全局数据
getApp: 我们一般在小程序里面,将多个组件都需要使用的数据,放到app.js里面,然后通过getApp()去用
使用过哪些小程序原生的组件和Api
这个就很多了,我记不大清了,
- 常用的组件比如
view text rich-text navagator导航 swiper轮播图比较复杂的就是媒体组件 image 地图组件map等 - 常用的api就很多了,我自己用过
- 印象比较深刻的就是:
微信登录 wx.login 微信支付 wx.requestPayment - 其他比较简单的就是:
发请求 wx.request, 编程式导航wx.navigateTo, 获取基本信息getUserInfo其他的记不太清了,看文档直接用,比较简单
- 印象比较深刻的就是:
uni-app开发的特点
- uni-app 可以编写一套代码,打包成14个平台,节约公司成本,快速搭建各个平台的产品。 我之前公司就用这个写过 微信小程序和 h5的项目,还比较好用,就是有些兼容性,有些细节需要注意
- 全部是vue的语法写小程序,上手无压力
- 注册时使用组件的时候,支持 easycom的模式。只要符合了基本的结构,不需要导入和注册,直接使用即可
- 技术选型是uni-app+uview-ui ; 原生小程序就是 原生语法+vantUI
说说微信小程序的生命周期函数有哪些?
首先小程序的生命周期有很多种,应用级别,页面界别和组件级别。开发uni-app的时候因为是vue的语法,所以还有vue的生命周期在里面。所以我们小程序 应用界别和页面级别的采用 小程序的生命周期。自定义组件 采用vue的生命周期
- 应用级别(小程序的),onLaunch —- App.vue文件里面
- 页面级别(小程序),onLoad —– 定义在pages数组里面或者分包里面的 vue文件
- 组件级别(vue的),created
整个小程序的生命周期:
- onLaunch: 小程序初始化时触发,全局只触发一次。
- onShow: 小程序启动或从后台进入前台时触发。
页面的生命周期:
- onLoad: 页面加载时触发,一个页面只会调用一次。
- onShow: 页面显示/切入前台时触发。
- onReady: 页面初次渲染完成时触发,一个页面只会调用一次。
当从当前页面切换到其他页面:
- onHide: 当前页面隐藏/切入后台时触发。
当从其他页面返回到当前页面:
- onShow: 当前页面重新显示/切入前台时触发。
当关闭当前页面或跳转到其他页面时:
- onUnload: 页面卸载时触发。
当整个小程序被切入后台或被关闭时:
- onHide: 小程序从前台进入后台时触发。
- onUnload: 小程序销毁时触发。
说说微信小程序中路由跳转的方式有哪些?区别?
- wx.navigateTo:
- 通过该方式进行页面跳转,会保留当前页面,新页面入栈。
- 应用场景:一般用于不同业务逻辑的页面之间的跳转,保留当前页面的状态,可以通过返回按钮返回上一页。
- wx.redirectTo:
- 通过该方式进行页面跳转,会关闭当前页面,新页面替换当前页面。
- 应用场景:用于替换当前页面,适用于一些不需要保留上一页状态的情况。
- wx.reLaunch:
- 关闭所有页面,打开到应用内的某个页面。
- 应用场景:适用于一些重新登录、进入新的模块等需要清空页面栈的情况。
- wx.switchTab:
- 跳转到 tabBar 页面,并关闭其他所有非 tabBar 页面。
- 应用场景:用于跳转到 tabBar 页面,比如从其他业务页面返回到首页。
- wx.navigateBack:
- 关闭当前页面,返回上一页面或多级页面。
- 应用场景:用于返回上一页或多级页面,可以指定返回的层级。
说说提高微信小程序的应用速度的手段有哪些?
提高微信小程序应用速度的效果可以通过以下手段来实现:
- 优化图片:
- 压缩图片:使用适当的图片压缩工具,减小图片文件大小。
- 使用合适的图片格式:选择适合场景的图片格式,如JPEG、PNG等。
- 使用小程序提供的图片CDN服务,加速图片加载。
- 减少HTTP请求:
- 尽量减少页面请求的资源数,合并和精简CSS、JavaScript文件。
- 使用小程序的本地存储功能,减少对服务器的频繁请求。
- 合理使用缓存:
- 合理使用小程序的缓存机制,减少重复请求。
- 对于不常变化的数据,可以通过缓存在本地减少网络请求次数。
- 异步加载:
- 使用异步加载方式,减小首屏加载时间。
- 对于一些不是首屏必需的内容,可以使用异步加载方式,提高页面渲染速度。
- 避免使用全局样式:
- 尽量避免使用全局样式,减少对整体样式的重新计算和渲染。
- 使用局部样式,限定渲染范围,提高渲染效率。
- 使用分包加载:
- 对于大型小程序,可以使用分包加载机制,将不同功能的页面分割成不同的包,减小首次加载时的体积。
小程序分包流程
小程序实现导航栏自定义
1 | { |
说说微信小程序的登录流程?
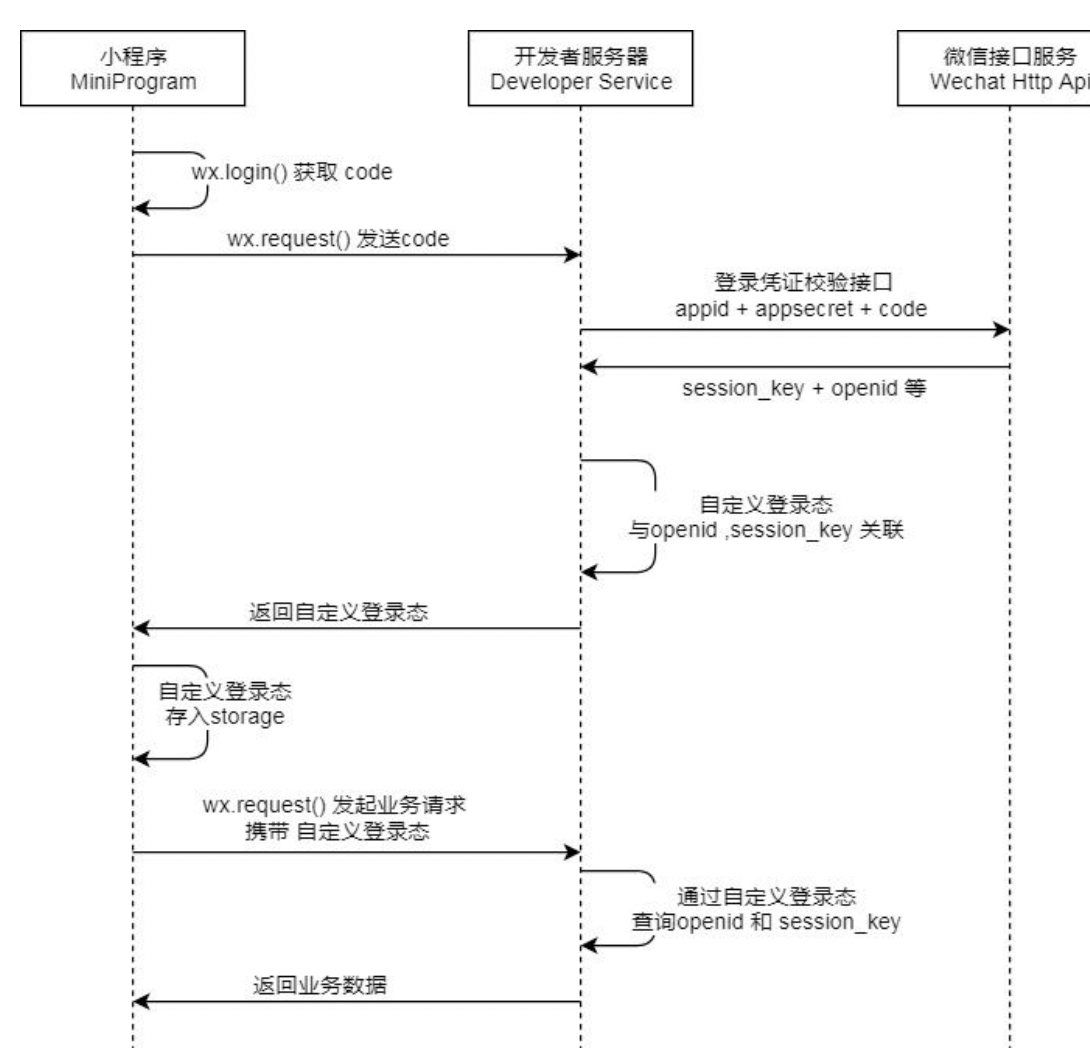
- 通过 wx.login() 获取到用户的code判断用户是否授权读取用户信息,调用wx.getUserInfo 读取用户数据
- 由于小程序后台授权域名无法授权微信的域名,所以需要自身后端调用微信服务器获取用户信息
- 通过 wx.request() 方法请求业务方服务器,后端把 appid , appsecret 和 code 一起发送到微信服务器。 appid 和 appsecret 都是微信提供的,可以在管理员后台找到
- 微信服务器返回了 openid 及本次登录的会话密钥 session_key
- 后端从数据库中查找 openid ,如果没有查到记录,说明该用户没有注册,如果有记录,则继续往下走
- session_key 是对用户数据进行加密签名的密钥。为了自身应用安全,session_key 不应该在网络上传输
- 然后生成 session并返回给小程序
- 小程序把 session 存到 storage 里面
- 下次请求时,先从 storage 里面读取,然后带给服务端
- 服务端对比 session 对应的记录,然后校验有效期
说说微信小程序的发布流程?
说说微信小程序的支付流程?
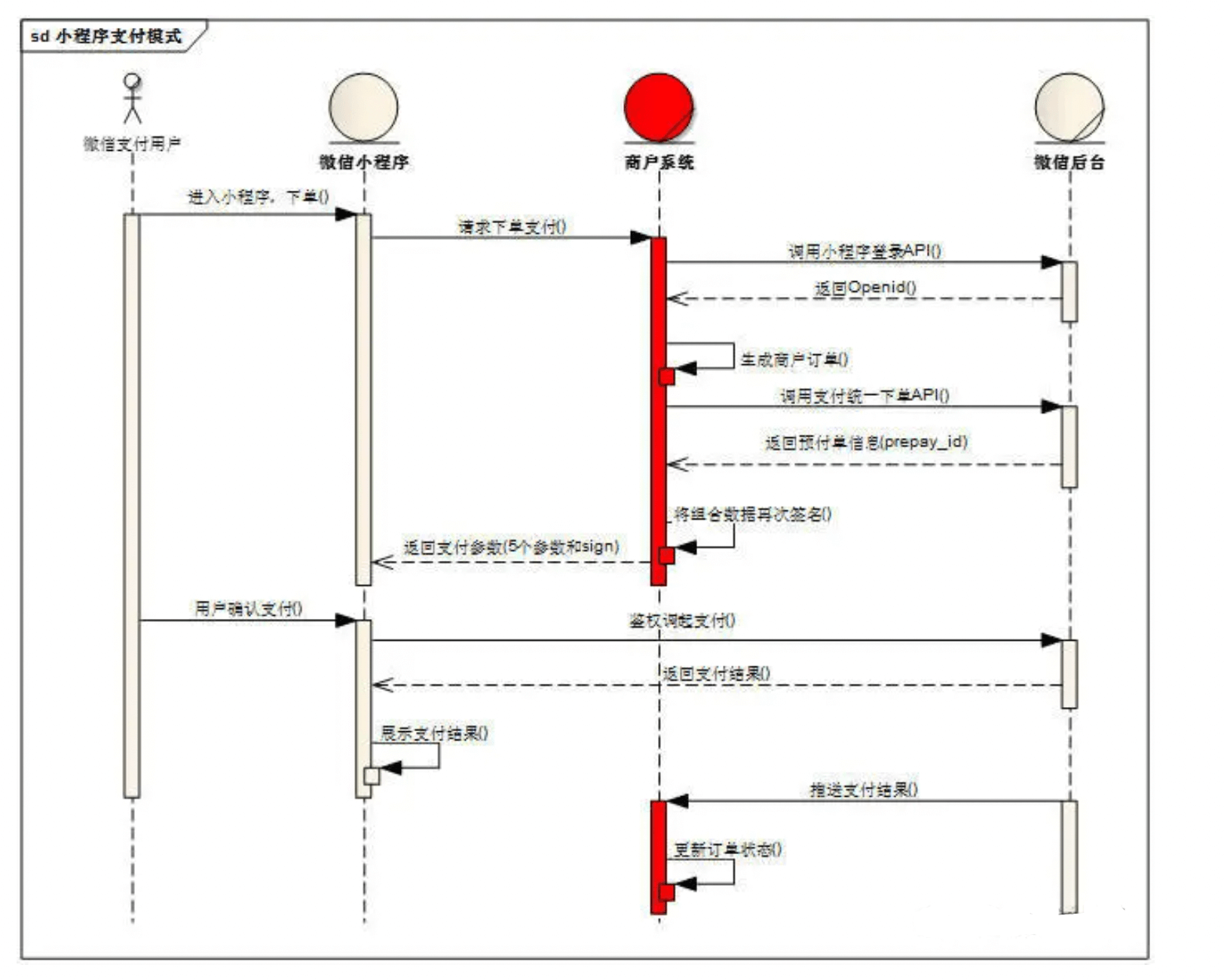
- 打开某小程序,点击直接下单
- wx.login获取用户临时登录凭证code,发送到后端服务器换取openId
- 在下单时,小程序需要将购买的商品Id,商品数量,以及用户的openId传送到服务器
- 服务器在接收到商品Id、商品数量、openId后,生成服务期订单数据,同时经过一定的签名算法,向微信支付发送请求,获取预付单信息(prepay_id),同时将获取的数据再次进行相应规则的签名,向小程序端响应必要的信息
- 小程序端在获取对应的参数后,调用wx.requestPayment()发起微信支付,唤醒支付工作台,进行支付
- 接下来的一些列操作都是由用户来操作的包括了微信支付密码,指纹等验证,确认支付之后执行鉴权调起支付
- 鉴权调起支付:在微信后台进行鉴权,微信后台直接返回给前端支付的结果,前端收到返回数据后对支付结果进行展示
- 推送支付结果:微信后台在给前端返回支付的结果后,也会向后台也返回一个支付结果,后台通过这个支付结果来更新订单的状态
调用支付接口的五个参数:
- appId(小程序ID): 这是你的微信小程序的唯一标识符,每个小程序都有一个独特的App ID。
- timeStamp(时间戳): 一个从1970年1月1日00:00:00至今的秒数,即当前的时间戳。
- nonceStr(随机字符串): 随机生成的字符串,用于防止重放攻击。
- package(数据包): 统一下单接口返回的 prepay_id 参数值,具体内容格式由微信支付定义。
- signType(签名类型): 签名算法,目前支持 HMAC-SHA256 和 MD5。
小程序和h5和pc端开发有什么不一样?
不一样的主要是交互方式上面,因为小程序屏幕比较小,很多pc电脑上的交互,手机上都用不了
小程序和h5有 上拉刷新,下拉加载的操作
小程序和h5有 左滑 右滑的操作, 做一些收藏和删除的业务 (自己打开pdd,京东购物车去操作一遍)
小程序和h5有 针对与 iphoneX 那种 刘海屏,底部安全区域的单独设置等等. constant env 具体的我忘记了
1
2padding-bottom: constant(safe-area-in`Set`-bottom); /* iOS 11.0 */
padding-bottom: env(safe-area-in`Set`-bottom); /* iOS 11.2 */
git
说说你对版本管理的理解?常用的版本管理工具有哪些?
版本管理是一种软件开发中重要的实践,用于追踪、管理和协调项目中的代码变更。版本管理有助于团队协作、追踪项目历史、恢复先前的状态,同时提供了一种备份和协同开发的机制。
分布式管理工具 git
集中式管理工具 svn
说说你对Git的理解?
说说Git中 fork, clone,branch这三个概念,有什么区别?
- Fork:
- 概念: Fork是在代码托管平台(如GitHub)上的一个操作,它创建了原始仓库的一个副本,这个副本在你的个人账户下。
- 用途: 主要用于贡献代码或在独立的分支上进行实验性开发。你可以在你自己的Fork中进行修改,然后通过Pull Request(PR)请求将你的修改合并到原始仓库中。
- Clone:
- 概念: Clone是从一个现有的Git仓库中复制整个仓库到本地。
- 用途: 用于获取代码的完整副本,以便在本地进行开发、测试和修改。Clone操作创建了一个连接到原始仓库的本地副本。
- Branch:
- 概念: Branch是指在一个Git仓库中创建的一个独立的分支,分支是仓库中的一个独立的开发路径。
- 用途: 用于在项目中并行开发多个功能或修复不同的bug。每个分支都可以有不同的提交历史,但它们可以在需要时合并在一起。
区别总结:
- Fork: 在代码托管平台上创建一个原始仓库的副本,通常用于贡献代码和提出修改请求。
- Clone: 从一个现有的Git仓库中复制整个仓库到本地,用于在本地进行开发和修改。
- Branch: 在一个Git仓库中创建的一个独立的开发路径,用于并行开发多个功能或修复不同的bug。
说说Git常用的命令有哪些?
git branch 分支名 新建新分支
git checkout 分支名 切换到指定分支
git remote add 远程分支名 远程仓库地址 建立远程仓库关联
git merge 分支名 分支合并
git init 初始化git 仓库
git add . 提交到暂存区
git commit -m “提交日志” 提交到本地git 仓库
git push 本地仓库推送到远程仓库
git pull 拉取远程仓库
git state 查看本地文件状态
git log 查看文件提交记录
说说Git 中 HEAD、工作树和索引之间的区别?
- HEAD:
- 概念:
HEAD是指向当前所在分支的引用,或者指向某个具体的提交(commit)。 - 作用: 在Git中,
HEAD用于标识当前工作目录所在的提交版本,也可以用于切换分支、查看历史提交等操作。在HEAD所指向的提交上进行的修改将会成为新的提交。
- 概念:
- 工作树(Working Tree):
- 概念: 工作树是指包含项目实际文件的目录,也就是你在本地计算机上的项目副本。
- 作用: 工作树中的文件可以进行编辑和修改,这些修改会在提交(commit)时被保存到Git仓库。工作树是开发者进行实际工作的地方,也是代码的可视化部分。
- 索引(Index):
- 概念: 索引是一个暂存区域,用于存储将要提交到Git仓库的修改。它是一个缓存区域,记录了工作树中所有文件的状态信息。
- 作用: 在进行提交前,可以通过将文件的修改添加到索引中,形成一个预备提交的状态。这样可以选择性地提交文件的部分修改,而不是一次性提交所有修改。
区别总结:
- HEAD: 表示当前所在分支的引用或者指向某个具体的提交,标识了当前工作目录所在的版本。
- 工作树(Working Tree): 是包含实际项目文件的目录,是开发者进行实际工作的地方,可以编辑和修改文件。
- 索引(Index): 是一个缓存区域,记录了将要提交到Git仓库的修改,可以选择性地添加和提交文件的部分修改。
说说对git pull 和 git fetch 的理解?有什么区别?
git pull:- 作用:
git pull是一条综合命令,它包含了从远程仓库获取更新(git fetch)和合并(git merge)两个步骤。 - 使用场景: 当你希望获取远程仓库的更新并将它们合并到本地分支时,可以使用
git pull。例如,git pull origin master将从远程的origin仓库的master分支获取更新并合并到当前本地分支。
- 作用:
git fetch:- 作用:
git fetch用于从远程仓库获取更新,但它并不会自动合并这些更新到当前分支。 - 使用场景: 当你只希望查看远程仓库的更新,而不进行合并操作时,可以使用
git fetch。它将远程仓库的变更下载到本地,但并不自动修改你的工作目录或当前分支。
- 作用:
区别总结:
git pull从远程仓库获取更新并尝试自动合并到当前分支,是git fetch和git merge的综合命令。git fetch从远程仓库获取更新,但不会自动合并到当前分支。这使得你可以预览远程仓库的变更,然后决定是否进行合并。
使用 git fetch 的一个常见场景是查看远程仓库的变更情况,然后再决定是否执行 git merge 或 git rebase 将变更合并到本地分支。这样可以避免意外的合并,给予开发者更大的控制权。
说说你对git stash 的理解?应用场景?
git stash 是一个用于保存当前工作目录和暂存区状态的命令。它允许开发者在切换分支或者处理其他任务之前,将未提交的修改暂时存储起来,以便后续恢复。
应用场景:
临时切换分支:
- 当你正在某个分支上工作,但需要切换到其他分支进行紧急修复或测试时,可以使用
git stash保存当前工作进度,切换分支,完成操作后再通过git stash apply恢复。
1
2
3
4
5egit stash # 保存当前工作进度
git checkout <branch> # 切换到其他分支
# 进行紧急修复或测试
git checkout <original-branch> # 切回原来的分支
git stash apply # 恢复之前保存的工作进度- 当你正在某个分支上工作,但需要切换到其他分支进行紧急修复或测试时,可以使用
保存未提交的修改:
- 当你在进行一些修改,但突然需要切换到其他任务时,可以使用
git stash将未提交的修改暂时存储,以免影响其他操作。
1
2
3git stash # 保存未提交的修改
# 进行其他任务
git stash apply # 恢复之前保存的修改- 当你在进行一些修改,但突然需要切换到其他任务时,可以使用
避免合并冲突:
- 在合并分支之前,如果当前分支有未提交的修改,可以使用
git stash避免与合并引起的冲突。
1
2
3git stash # 保存当前分支的修改
git pull origin <branch> # 从远程拉取最新代码并合并
git stash apply # 恢复之前保存的修改- 在合并分支之前,如果当前分支有未提交的修改,可以使用
注意事项:
git stash不仅会保存工作目录中的修改,还会保存暂存区(Index)的状态。git stash默认会保存所有未提交的修改,包括新添加的文件和未追踪的文件。- 可以使用
git stash save "message"添加一条描述信息,以便在恢复时更容易理解每个 stash 的目的。
说说你对git rebase 和 git merge的理解?区别?
Git Rebase:
git rebase是将一个分支的修改合并到另一个分支的过程。通过重新设置分支的基点,使得提交历史更为线性,避免了合并产生的额外的合并提交。通常用于保持提交历史的整洁。
1
2git checkout feature-branch
git rebase mainGit Merge:
git merge是将一个分支的修改合并到另一个分支的过程。它会创建一个新的合并提交,将两个分支的修改合并在一起。这会在提交历史中产生一个新的合并节点。
1
2git checkout main
git merge feature-branch
区别:
- 提交历史的形状:
- Rebase: 通过
git rebase合并的提交历史更加线性,没有合并节点,看起来更加整洁。 - Merge: 通过
git merge合并的提交历史中会产生合并节点,形成分叉的结构。
- Rebase: 通过
- 合并方式:
- Rebase: 会将被合并分支的提交在目标分支的最新提交之后逐个应用,形成一系列新的提交。
- Merge: 会创建一个新的合并提交,将两个分支的修改合并在一起,并在提交历史中生成一个合并节点。
- 历史清晰性:
- Rebase: 通过
git rebase可以保持提交历史的整洁和线性,但可能会导致冲突。 - Merge: 通过
git merge可以保留原始分支的完整历史,但会在提交历史中产生合并节点。
- Rebase: 通过
- 冲突处理:
- Rebase: 如果在
git rebase过程中发生冲突,需要逐个解决每个冲突。 - Merge: 如果在
git merge过程中发生冲突,需要解决一次合并冲突,然后提交。
- Rebase: 如果在
选择使用场景:
Rebase:
- 用于个人分支,以保持整洁的提交历史。
- 不推荐对已经共享给其他开发者的分支进行 rebase。
1
2git checkout feature-branch
git rebase mainMerge:
- 用于合并多个开发者共享的分支,以保留每个开发者的独立提交历史。
- 在进行合并时,可以使用
--no-ff选项以保留合并提交。
1
2git checkout main
git merge feature-branch --no-ff
说说 git 发生冲突的场景?如何解决?
说说你对git reset 和 git revert 的理解?区别?
Git Reset:
git reSet`` 用于将当前分支的 HEAD 指针移动到指定的提交,并可选择是否更新工作目录和暂存区。它可以用于撤销提交、移动分支等操作。1
git reset <commit>
Git Revert:
git revert用于创建新的提交,以撤销先前的提交。它不会移动分支,而是在提交历史中添加一个新的提交,该提交的变更是先前提交的逆操作。1
git revert <commit>
区别:
- 影响提交历史:
- Reset: 通过
git reset可以修改提交历史,将 HEAD 指针移动到指定的提交,从而删除一些提交。这会改变提交历史,不建议对已共享的提交进行 reset 操作。 - Revert: 通过
git revert创建一个新的提交,以保持提交历史的完整性。它不修改已有的提交,而是添加新的提交作为撤销操作的记录。
- Reset: 通过
- 适用场景:
- Reset: 适用于本地仓库中的操作,特别是在分支上进行实验性的提交,但不建议在共享的分支上使用 reset。
- Revert: 适用于已经共享的分支,因为它不改变提交历史,而是添加新的提交来撤销之前的更改。
- 风险因素:
- Reset: 使用
git reset可能会导致丢失提交,因为它会直接移动 HEAD 指针。 - Revert: 使用
git revert通常比较安全,因为它不会改变原有的提交历史,而是创建新的提交来撤销变更。
- Reset: 使用
使用场景:
Reset:
- 用于本地分支上的实验性提交,当需要撤销一些提交时。
- 小组内的协作中,可以通过 re
Set撤销尚未共享的提交。
1
git reSet HEAD~1 # 撤销最后一次提交
Revert:
- 用于共享的分支上,当需要撤销已经共享的提交时。
- 适用于已经推送到远程仓库的分支,以免影响其他开发者。
1
git revert <commit> # 撤销指定提交
注意事项:
- 在使用
git reset时,需要谨慎操作,因为它会修改提交历史,可能导致数据丢失。 - 在使用
git revert时,需要处理可能发生的冲突,因为它会创建新的提交。
git分支规范
主分支 master/main
测试分支 release
开发分支 dev
git如何合并分支部分代码
在Git中,你可以使用 git cherry-pick 命令来合并某个提交或一系列提交到当前分支。这允许你选择性地合并分支中的部分代码,而不是整个分支。
以下是使用 git cherry-pick 的步骤:
查找提交 ID:
- 首先,使用
git log命令查找要合并的提交的提交 ID。
1
git log
- 首先,使用
切换到目标分支:
- 切换到你想要将代码合并到的目标分支。
1
git checkout <target-branch>
执行 cherry-pick:
- 使用
git cherry-pick命令并提供要合并的提交 ID。
1
git cherry-pick <commit-id>
- 使用
如果要合并一系列连续的提交,可以使用 commit 范围:
1 | git cherry-pick <start-commit-id>^..<end-commit-id> |
这里 ^ 表示排除 start-commit-id 自身。
处理冲突(如果有):
- 如果合并过程中发生冲突,需要手动解决冲突,然后使用
git add和git cherry-pick --continue完成合并。
1
2git add <conflicted-file>
git cherry-pick --continue- 如果合并过程中发生冲突,需要手动解决冲突,然后使用
完成:
- 合并完成后,可以继续进行其他操作或者提交合并结果。
1
git commit
请注意,git cherry-pick 可能会引入冲突,特别是当合并的提交依赖于目标分支的其他修改时。在使用 git cherry-pick 时,确保理解合并的影响,并在需要时手动解决冲突。
如何切换新分支且不产生新记录
TypeScript
说说你对 TypeScript 的理解?与 JavaScript 的区别?
TypeScript 是 JavaScript 的类型的超集,支持ES6语法,支持面向对象编程的概念,如类、接口、继承、泛型等
超集,不得不说另外一个概念,子集,怎么理解这两个呢,举个例子,如果一个集合 A 里面的的所有元素集合 B 里面都存在,那么我们可以理解集合 B 是集合 A 的超集,集合 A 为集合 B 的子集
其是一种静态类型检查的语言,提供了类型注解,在代码编译阶段就可以检查出数据类型的错误
同时扩展了JavaScript 的语法,所以任何现有的JavaScript 程序可以不加改变的在 TypeScript 下工作
为了保证兼容性,TypeScript 在编译阶段需要编译器编译成纯 JavaScript 来运行,是为大型应用之开发而设计的语言,如下:
ts 文件如下:
1 | const hello: string = "Hello World!"; |
编译文件后:
1 | const hello = "Hello World!"; |
二、特性
TypeScript 的特性主要有如下:
- 类型批注和编译时类型检查 :在编译时批注变量类型
- 类型推断:ts 中没有批注变量类型会自动推断变量的类型
- 类型擦除:在编译过程中批注的内容和接口会在运行时利用工具擦除
- 接口:ts 中用接口来定义对象类型
- 枚举:用于取值被限定在一定范围内的场景
- Mixin:可以接受任意类型的值
- 泛型编程:写代码时使用一些以后才指定的类型
- 名字空间:名字只在该区域内有效,其他区域可重复使用该名字而不冲突
- 元组:元组合并了不同类型的对象,相当于一个可以装不同类型数据的数组
- …
类型批注
通过类型批注提供在编译时启动类型检查的静态类型,这是可选的,而且可以忽略而使用 JavaScript 常规的动态类型
1 | function Add(left: number, right: number): number { |
对于基本类型的批注是 number、bool 和 string,而弱或动态类型的结构则是 any 类型
类型推断
当类型没有给出时,TypeScript 编译器利用类型推断来推断类型,如下:
1 | let str = "string"; |
变量 str 被推断为字符串类型,这种推断发生在初始化变量和成员,设置默认参数值和决定函数返回值时
如果缺乏声明而不能推断出类型,那么它的类型被视作默认的动态 any 类型
接口
接口简单来说就是用来描述对象的类型 数据的类型有 number、null、string 等数据格式,对象的类型就是用接口来描述的
1 | interface Person { |
三、区别
- TypeScript 是 JavaScript 的超集,扩展了 JavaScript 的语法
- TypeScript 可处理已有的 JavaScript 代码,并只对其中的 TypeScript 代码进行编译
- TypeScript 文件的后缀名 .ts (.ts,.tsx,.dts),JavaScript 文件是 .js
- 在编写 TypeScript 的文件的时候就会自动编译成 js 文件
更多的区别如下图所示:
说说 typescript 的数据类型有哪些?
typescript 的数据类型主要有如下:
boolean(布尔类型)
number(数字类型)
string(字符串类型)
array(数组类型)
tuple(元组类型)
enum(枚举类型)
any(任意类型)
null 和 undefined 类型
void 类型
never 类型
object 对象类型
#boolean
布尔类型
1 | let flag:boolean = true; |
#number
数字类型,和javascript一样,typescript的数值类型都是浮点数,可支持二进制、八进制、十进制和十六进制
1 | let num:number = 123; |
进制表示:
1 | let decLiteral: number = 6; // 十进制 |
#string
字符串类型,和JavaScript一样,可以使用双引号(”)或单引号(’)表示字符串
1 | let str:string = 'this is ts'; |
作为超集,当然也可以使用模版字符串``进行包裹,通过 ${} 嵌入变量
1 | let name: string = `Gene`; |
#array
数组类型,跟javascript一致,通过[]进行包裹,有两种写法:
方式一:元素类型后面接上 []
1 | let arr:string[] = ['12', '23']; |
方式二:使用数组泛型,Array<元素类型>:
1 | let arr:Array<number> = [1, 2]; |
#tuple
元祖类型,允许表示一个已知元素数量和类型的数组,各元素的类型不必相同
1 | let tupleArr:[number, string, boolean]; |
赋值的类型、位置、个数需要和定义(生明)的类型、位置、个数一致
#enum
enum类型是对JavaScript标准数据类型的一个补充,使用枚举类型可以为一组数值赋予友好的名字
1 | enum Color {Red, Green, Blue} |
#any
可以指定任何类型的值,在编程阶段还不清楚类型的变量指定一个类型,不希望类型检查器对这些值进行检查而是直接让它们通过编译阶段的检查,这时候可以使用any类型
使用any类型允许被赋值为任意类型,甚至可以调用其属性、方法
1 | let num:any = 123; |
定义存储各种类型数据的数组时,示例代码如下:
1 | let arrayList: any[] = [1, false, 'fine']; |
在JavaScript 中 null表示 “什么都没有”,是一个只有一个值的特殊类型,表示一个空对象引用,而undefined表示一个没有设置值的变量
默认情况下null和undefined是所有类型的子类型, 就是说你可以把 null和 undefined赋值给 number类型的变量
1 | let num:number | undefined; // 数值类型 或者 undefined |
但是ts配置了–strictNullChecks标记,null和undefined只能赋值给void和它们各自
#void
用于标识方法返回值的类型,表示该方法没有返回值。
1 | function hello(): void { |
#never
never是其他类型 (包括null和 undefined)的子类型,可以赋值给任何类型,代表从不会出现的值
但是没有类型是 never 的子类型,这意味着声明 never 的变量只能被 never 类型所赋值。
never 类型一般用来指定那些总是会抛出异常、无限循环
1 | let a:never; |
#object
对象类型,非原始类型,常见的形式通过{}进行包裹
1 | let obj:object; |
#三、总结
和javascript基本一致,也分成:
基本类型
引用类型
在基础类型上,typescript增添了void、any、emum等原始类型
说说你对 TypeScript 中枚举类型的理解?应用场景?
一、是什么
枚举是一个被命名的整型常数的集合,用于声明一组命名的常数,当一个变量有几种可能的取值时,可以将它定义为枚举类型
通俗来说,枚举就是一个对象的所有可能取值的集合
在日常生活中也很常见,例如表示星期的SUNDAY、MONDAY、TUESDAY、WEDNESDAY、THURSDAY、FRIDAY、SATURDAY就可以看成是一个枚举
枚举的说明与结构和联合相似,其形式为:
1 | enum 枚举名{ |
#二、使用
枚举的使用是通过enum关键字进行定义,形式如下:
1 | enum xxx { ... } |
类型可以分成:
数字枚举
字符串枚举
异构枚举
#数字枚举
当我们声明一个枚举类型是,虽然没有给它们赋值,但是它们的值其实是默认的数字类型,而且默认从0开始依次累加:
1 | enum Direction { |
如果我们将第一个值进行赋值后,后面的值也会根据前一个值进行累加1:
1 | enum Direction { |
#字符串枚举
枚举类型的值其实也可以是字符串类型:
1 | enum Direction { |
如果设定了一个变量为字符串之后,后续的字段也需要赋值字符串,否则报错:
1 | enum Direction { |
#异构枚举
即将数字枚举和字符串枚举结合起来混合起来使用,如下:
1 | enum BooleanLikeHeterogeneousEnum { |
通常情况下我们很少会使用异构枚举
#本质
现在一个枚举的案例如下:
1 | enum Direction { |
通过编译后,javascript如下:
1 | var Direction; |
上述代码可以看到, Direction[Direction[“Up”] = 0] = “Up”可以分成
1 | Direction["Up"] = 0 |
所以定义枚举类型后,可以通过正反映射拿到对应的值,如下:
1 | enum Direction { |
并且多处定义的枚举是可以进行合并操作,如下:
1 | enum Direction { |
编译后,js代码如下:
1 | var Direction; |
可以看到,Direction对象属性回叠加
#三、应用场景
就拿回生活的例子,后端返回的字段使用 0 - 6 标记对应的日期,这时候就可以使用枚举可提高代码可读性,如下:
1 | enum Days {Sun, Mon, Tue, Wed, Thu, Fri, Sat}; |
包括后端日常返回0、1 等等状态的时候,我们都可以通过枚举去定义,这样可以提高代码的可读性,便于后续的维护
说说你对 TypeScript 中接口的理解?应用场景?
一、是什么
接口是一系列抽象方法的声明,是一些方法特征的集合,这些方法都应该是抽象的,需要由具体的类去实现,然后第三方就可以通过这组抽象方法调用,让具体的类执行具体的方法
简单来讲,一个接口所描述的是一个对象相关的属性和方法,但并不提供具体创建此对象实例的方法
typescript的核心功能之一就是对类型做检测,虽然这种检测方式是“鸭式辨型法”,而接口的作用就是为为这些类型命名和为你的代码或第三方代码定义一个约定
#二、使用方式
接口定义如下:
1 | interface interface_name { |
例如有一个函数,这个函数接受一个 User 对象,然后返回这个 User 对象的 name 属性:
1 | const getUserName = (user) => user.name |
可以看到,参数需要有一个user的name属性,可以通过接口描述user参数的结构
1 | interface User { |
这些属性并不一定全部实现,上述传入的对象必须拥有name和age属性,否则typescript在编译阶段会报错,如下图:
如果不想要age属性的话,这时候可以采用可选属性,如下表示:
1 | interface User { |
这时候age属性则可以是number类型或者undefined类型
有些时候,我们想要一个属性变成只读属性,在typescript只需要使用readonly声明,如下:
1 | interface User { |
当我们修改属性的时候,就会出现警告,如下所示:
这是属性中有一个函数,可以如下表示:
1 | interface User { |
如果传递的对象不仅仅是上述的属性,这时候可以使用:
类型推断
1 | interface User { |
接口还能实现继承,如下图:
也可以继承多个,父类通过逗号隔开,如下:
1 | interface Father { |
#三、应用场景
例如在javascript中定义一个函数,用来获取用户的姓名和年龄:
1 | const getUserInfo = function(user) { |
如果多人开发的都需要用到这个函数的时候,如果没有注释,则可能出现各种运行时的错误,这时候就可以使用接口定义参数变量:
// 先定义一个接口
1 | interface IUser { |
包括后面讲到类的时候也会应用到接口
说说你对 TypeScript 中类的理解?应用场景?
一、是什么
类(Class)是面向对象程序设计(OOP,Object-Oriented Programming)实现信息封装的基础
类是一种用户定义的引用数据类型,也称类类型
传统的面向对象语言基本都是基于类的,JavaScript 基于原型的方式让开发者多了很多理解成本
在 ES6 之后,JavaScript 拥有了 class 关键字,虽然本质依然是构造函数,但是使用起来已经方便了许多
但是JavaScript 的class依然有一些特性还没有加入,比如修饰符和抽象类
TypeScript 的 class 支持面向对象的所有特性,比如 类、接口等
#二、使用方式
定义类的关键字为 class,后面紧跟类名,类可以包含以下几个模块(类的数据成员):
字段 : 字段是类里面声明的变量。字段表示对象的有关数据。
构造函数: 类实例化时调用,可以为类的对象分配内存。
方法: 方法为对象要执行的操作
如下例子:
1 | class Car { |
}
#继承
类的继承使用过extends的关键字
1 | class Animal { |
Dog是一个 派生类,它派生自 Animal 基类,派生类通常被称作子类,基类通常被称作 超类
Dog类继承了Animal类,因此实例dog也能够使用Animal类move方法
同样,类继承后,子类可以对父类的方法重新定义,这个过程称之为方法的重写,通过super关键字是对父类的直接引用,该关键字可以引用父类的属性和方法,如下:
1 | class PrinterClass { |
#修饰符
可以看到,上述的形式跟ES6十分的相似,typescript在此基础上添加了三种修饰符:
公共 public:可以自由的访问类程序里定义的成员
私有 private:只能够在该类的内部进行访问
受保护 protect:除了在该类的内部可以访问,还可以在子类中仍然可以访问
#私有修饰符
只能够在该类的内部进行访问,实例对象并不能够访问
并且继承该类的子类并不能访问,如下图所示:
#受保护修饰符
跟私有修饰符很相似,实例对象同样不能访问受保护的属性,如下:
有一点不同的是 protected 成员在子类中仍然可以访问
除了上述修饰符之外,还有只读修饰符
#只读修饰符
通过readonly关键字进行声明,只读属性必须在声明时或构造函数里被初始化,如下:
除了实例属性之外,同样存在静态属性
#静态属性
这些属性存在于类本身上面而不是类的实例上,通过static进行定义,访问这些属性需要通过 类型.静态属性 的这种形式访问,如下所示:
1 | class Square { |
上述的类都能发现一个特点就是,都能够被实例化,在 typescript中,还存在一种抽象类
#抽象类
抽象类做为其它派生类的基类使用,它们一般不会直接被实例化,不同于接口,抽象类可以包含成员的实现细节
abstract关键字是用于定义抽象类和在抽象类内部定义抽象方法,如下所示:
1 | abstract class Animal { |
这种类并不能被实例化,通常需要我们创建子类去继承,如下:
1 | class Cat extends Animal { |
#三、应用场景
除了日常借助类的特性完成日常业务代码,还可以将类(class)也可以作为接口,尤其在 React 工程中是很常用的,如下:
export default class Carousel extends React.Component<Props, State> {}
由于组件需要传入 props 的类型 Props ,同时有需要设置默认 props 即 defaultProps,这时候更加适合使用class作为接口
先声明一个类,这个类包含组件 props 所需的类型和初始值:
1 | // props的类型 |
当我们需要传入 props 类型的时候直接将 Props 作为接口传入,此时 Props 的作用就是接口,而当需要我们设置defaultProps初始值的时候,我们只需要:
1 | public static defaultProps = new Props() |
Props 的实例就是 defaultProps 的初始值,这就是 class作为接口的实际应用,我们用一个 class 起到了接口和设置初始值两个作用,方便统一管理,减少了代码量
说说你对 TypeScript 中函数的理解?与 JavaScript 函数的区别?
一、是什么
函数是JavaScript 应用程序的基础,帮助我们实现抽象层、模拟类、信息隐藏和模块
在TypeScript 里,虽然已经支持类、命名空间和模块,但函数仍然是主要定义行为的方式,TypeScript 为 JavaScript 函数添加了额外的功能,丰富了更多的应用场景
函数类型在 TypeScript 类型系统中扮演着非常重要的角色,它们是可组合系统的核心构建块
#二、使用方式
跟javascript 定义函数十分相似,可以通过funciton 关键字、箭头函数等形式去定义,例如下面一个简单的加法函数:
1 | const add = (a: number, b: number) => a + b |
上述只定义了函数的两个参数类型,这个时候整个函数虽然没有被显式定义,但是实际上TypeScript 编译器是能够通过类型推断到这个函数的类型,如下图所示:
当鼠标放置在第三行add函数名的时候,会出现完整的函数定义类型,通过: 的形式来定于参数类型,通过 => 连接参数和返回值类型
当我们没有提供函数实现的情况下,有两种声明函数类型的方式,如下所示:
1 | // 方式一 |
#可选参数
当函数的参数可能是不存在的,只需要在参数后面加上 ? 代表参数可能不存在,如下:
1 | const add = (a: number, b?: number) => a + (b ? b : 0) |
这时候参数b可以是number类型或者undefined类型,即可以传一个number类型或者不传都可以
#剩余类型
剩余参数与JavaScript的语法类似,需要用 … 来表示剩余参数
如果剩余参数 rest 是一个由number类型组成的数组,则如下表示:
1 | const add = (a: number, ...rest: number[]) => rest.reduce(((a, b) => a + b), a) |
#函数重载
允许创建数项名称相同但输入输出类型或个数不同的子程序,它可以简单地称为一个单独功能可以执行多项任务的能力
关于typescript函数重载,必须要把精确的定义放在前面,最后函数实现时,需要使用 |操作符或者?操作符,把所有可能的输入类型全部包含进去,用于具体实现
这里的函数重载也只是多个函数的声明,具体的逻辑还需要自己去写,typescript并不会真的将你的多个重名 function的函数体进行合并
例如我们有一个add函数,它可以接收 string类型的参数进行拼接,也可以接收 number 类型的参数进行相加,如下:
1 | // 上边是声明 |
三、区别
从上面可以看到:
从定义的方式而言,typescript 声明函数需要定义参数类型或者声明返回值类型
typescript 在参数中,添加可选参数供使用者选择
typescript 增添函数重载功能,使用者只需要通过查看函数声明的方式,即可知道函数传递的参数个数以及类型
说说你对 TypeScript 中泛型的理解?应用场景?
一、是什么
泛型程序设计(generic programming)是程序设计语言的一种风格或范式
泛型允许我们在强类型程序设计语言中编写代码时使用一些以后才指定的类型,在实例化时作为参数指明这些类型 在typescript中,定义函数,接口或者类的时候,不预先定义好具体的类型,而在使用的时候在指定类型的一种特性
假设我们用一个函数,它可接受一个 number 参数并返回一个number 参数,如下写法:
1 | function returnItem (para: number): number { |
如果我们打算接受一个 string 类型,然后再返回 string类型,则如下写法:
1 | function returnItem (para: string): string { |
上述两种编写方式,存在一个最明显的问题在于,代码重复度比较高
虽然可以使用 any类型去替代,但这也并不是很好的方案,因为我们的目的是接收什么类型的参数返回什么类型的参数,即在运行时传入参数我们才能确定类型
这种情况就可以使用泛型,如下所示:
1 | function returnItem<T>(para: T): T { |
可以看到,泛型给予开发者创造灵活、可重用代码的能力
#二、使用方式
泛型通过<>的形式进行表述,可以声明:
函数
接口
类
#函数声明
声明函数的形式如下:
1 | function returnItem<T>(para: T): T { |
定义泛型的时候,可以一次定义多个类型参数,比如我们可以同时定义泛型 T 和 泛型 U:
1 | function swap<T, U>(tuple: [T, U]): [U, T] { |
#接口声明
声明接口的形式如下:
1 | interface ReturnItemFn<T> { |
那么当我们想传入一个number作为参数的时候,就可以这样声明函数:
1 | const returnItem: ReturnItemFn<number> = para => para |
#类声明
使用泛型声明类的时候,既可以作用于类本身,也可以作用与类的成员函数
下面简单实现一个元素同类型的栈结构,如下所示:
1 | class Stack<T> { |
使用方式如下:
1 | const stack = new Stacn<number>() |
如果上述只能传递 string 和 number 类型,这时候就可以使用
除了上述的形式,泛型更高级的使用如下:
例如要设计一个函数,这个函数接受两个参数,一个参数为对象,另一个参数为对象上的属性,我们通过这两个参数返回这个属性的值
这时候就设计到泛型的索引类型和约束类型共同实现
#索引类型、约束类型
索引类型 keyof T 把传入的对象的属性类型取出生成一个联合类型,这里的泛型 U 被约束在这个联合类型中,如下所示:
1 | function getValue<T extends object, U extends keyof T>(obj: T, key: U) { |
上述为什么需要使用泛型约束,而不是直接定义第一个参数为 object类型,是因为默认情况 object 指的是{},而我们接收的对象是各种各样的,一个泛型来表示传入的对象类型,比如 T extends object
使用如下图所示:
#多类型约束
例如如下需要实现两个接口的类型约束:
1 | interface FirstInterface { |
可以创建一个接口继承上述两个接口,如下:
1 | interface ChildInterface extends FirstInterface, SecondInterface { |
正确使用如下:
1 | class Demo<T extends ChildInterface> { |
通过泛型约束就可以达到多类型约束的目的
说说你对 TypeScript 中高级类型的理解?有哪些?
一、是什么
除了string、number、boolean 这种基础类型外,在 typescript 类型声明中还存在一些高级的类型应用
这些高级类型,是typescript为了保证语言的灵活性,所使用的一些语言特性。这些特性有助于我们应对复杂多变的开发场景
#二、有哪些
常见的高级类型有如下:
交叉类型
联合类型
类型别名
类型索引
类型约束
映射类型
条件类型
#交叉类型
通过 & 将多个类型合并为一个类型,包含了所需的所有类型的特性,本质上是一种并的操作
语法如下:
T & U
适用于对象合并场景,如下将声明一个函数,将两个对象合并成一个对象并返回:
1 | function extend<T , U>(first: T, second: U) : T & U { |
#联合类型
联合类型的语法规则和逻辑 “或” 的符号一致,表示其类型为连接的多个类型中的任意一个,本质上是一个交的关系
语法如下:
1 | T | U |
例如 number | string | boolean 的类型只能是这三个的一种,不能共存
如下所示:
1 | function formatCommandline(command: string[] | string) { |
#类型别名
类型别名会给一个类型起个新名字,类型别名有时和接口很像,但是可以作用于原始值、联合类型、元组以及其它任何你需要手写的类型
可以使用 type SomeName = someValidTypeAnnotation的语法来创建类型别名:
1 | type some = boolean | string |
此外类型别名可以是泛型:
1 | type Container<T> = { value: T }; |
也可以使用类型别名来在属性里引用自己:
1 | type Tree<T> = { |
可以看到,类型别名和接口使用十分相似,都可以描述一个对象或者函数
两者最大的区别在于,interface只能用于定义对象类型,而 type 的声明方式除了对象之外还可以定义交叉、联合、原始类型等,类型声明的方式适用范围显然更加广泛
#类型索引
keyof 类似于 Object.keys ,用于获取一个接口中 Key 的联合类型。
1 | interface Button { |
#类型约束
通过关键字 extend 进行约束,不同于在 class 后使用 extends 的继承作用,泛型内使用的主要作用是对泛型加以约束
1 | type Ba`Set`ype = string | number | boolean |
类型约束通常和类型索引一起使用,例如我们有一个方法专门用来获取对象的值,但是这个对象并不确定,我们就可以使用 extends 和 keyof 进行约束。
1 | function getValue<T, K extends keyof T>(obj: T, key: K) { |
#映射类型
通过 in 关键字做类型的映射,遍历已有接口的 key 或者是遍历联合类型,如下例子:
1 | type Readonly<T> = { |
上述的结构,可以分成这些步骤:
keyof T:通过类型索引 keyof 的得到联合类型 ‘a’ | ‘b’
P in keyof T 等同于 p in ‘a’ | ‘b’,相当于执行了一次 forEach 的逻辑,遍历 ‘a’ | ‘b’
所以最终ReadOnlyObj的接口为下述:
1 | interface ReadOnlyObj { |
#条件类型
条件类型的语法规则和三元表达式一致,经常用于一些类型不确定的情况。
1 | T extends U ? X : Y |
上面的意思就是,如果 T 是 U 的子集,就是类型 X,否则为类型 Y
#三、总结
可以看到,如果只是掌握了 typeScript 的一些基础类型,可能很难游刃有余的去使用 typeScript,需要了解一些typescript的高阶用法
并且typescript在版本的迭代中新增了很多功能,需要不断学习与掌握
说说你对 TypeScript 装饰器的理解?应用场景?
一、是什么
装饰器是一种特殊类型的声明,它能够被附加到类声明,方法, 访问符,属性或参数上
是一种在不改变原类和使用继承的情况下,动态地扩展对象功能
同样的,本质也不是什么高大上的结构,就是一个普通的函数,@expression 的形式其实是Object.defineProperty的语法糖
expression求值后必须也是一个函数,它会在运行时被调用,被装饰的声明信息做为参数传入
#二、使用方式
由于typescript是一个实验性特性,若要使用,需要在tsconfig.json文件启动,如下:
1 | { |
typescript装饰器的使用和javascript基本一致
类的装饰器可以装饰:
类
方法/属性
参数
访问器
#类装饰
例如声明一个函数 addAge 去给 Class 的属性 age 添加年龄.
1 | function addAge(constructor: Function) { |
上述代码,实际等同于以下形式:
1 | Person = addAge(function Person() { ... }); |
上述可以看到,当装饰器作为修饰类的时候,会把构造器传递进去。 constructor.prototype.age 就是在每一个实例化对象上面添加一个 age 属性
#方法/属性装饰
同样,装饰器可以用于修饰类的方法,这时候装饰器函数接收的参数变成了:
target:对象的原型
propertyKey:方法的名称
descriptor:方法的属性描述符
可以看到,这三个属性实际就是Object.defineProperty的三个参数,如果是类的属性,则没有传递第三个参数
如下例子:
1 | // 声明装饰器修饰方法/属性 |
输出如下图所示:
#参数装饰
接收3个参数,分别是:
1 | target :当前对象的原型 |
输入如下图:
#访问器装饰
使用起来方式与方法装饰一致,如下:
1 | function modification(target: Object, propertyKey: string, descriptor: PropertyDescriptor) { |
#装饰器工厂
如果想要传递参数,使装饰器变成类似工厂函数,只需要在装饰器函数内部再函数一个函数即可,如下:
1 | function addAge(age: number) { |
#执行顺序
当多个装饰器应用于一个声明上,将由上至下依次对装饰器表达式求值,求值的结果会被当作函数,由下至上依次调用,例如如下:
1 | function f() { |
#三、应用场景
可以看到,使用装饰器存在两个显著的优点:
代码可读性变强了,装饰器命名相当于一个注释
在不改变原有代码情况下,对原来功能进行扩展
后面的使用场景中,借助装饰器的特性,除了提高可读性之后,针对已经存在的类,可以通过装饰器的特性,在不改变原有代码情况下,对原来功能进行扩展
说说对 TypeScript 中命名空间与模块的理解?区别?
一、模块
TypeScript 与ECMAScript 2015 一样,任何包含顶级 import 或者 export 的文件都被当成一个模块
相反地,如果一个文件不带有顶级的import或者export声明,那么它的内容被视为全局可见的
例如我们在在一个 TypeScript 工程下建立一个文件 1.ts,声明一个变量a,如下:
1 | const a = 1 |
然后在另一个文件同样声明一个变量a,这时候会出现错误信息
提示重复声明a变量,但是所处的空间是全局的
如果需要解决这个问题,则通过import或者export引入模块系统即可,如下:
1 | const a = 10; |
通过import 引入模块,如下:
1 | import { a, Person } from './export'; |
#二、命名空间
命名空间一个最明确的目的就是解决重名问题
命名空间定义了标识符的可见范围,一个标识符可在多个名字空间中定义,它在不同名字空间中的含义是互不相干的
这样,在一个新的名字空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,因为已有的定义都处于其他名字空间中
TypeScript 中命名空间使用 namespace 来定义,语法格式如下:
1 | namespace SomeNameSpaceName { |
以上定义了一个命名空间 SomeNameSpaceName,如果我们需要在外部可以调用 SomeNameSpaceName 中的类和接口,则需要在类和接口添加 export 关键字
使用方式如下:
SomeNameSpaceName.SomeClassName
命名空间本质上是一个对象,作用是将一系列相关的全局变量组织到一个对象的属性,如下:
1 | namespace Letter { |
编译成js如下:
1 | var Letter; |
#三、区别
命名空间是位于全局命名空间下的一个普通的带有名字的 JavaScript 对象,使用起来十分容易。但就像其它的全局命名空间污染一样,它很难去识别组件之间的依赖关系,尤其是在大型的应用中
像命名空间一样,模块可以包含代码和声明。 不同的是模块可以声明它的依赖
在正常的TS项目开发过程中并不建议用命名空间,但通常在通过 d.ts 文件标记 js 库类型的时候使用命名空间,主要作用是给编译器编写代码的时候参考使用
说说如何在 React 项目中应用 TypeScript?
说说如何在Vue项目中应用TypeScript?
node.js
说说你对 Node.js 的理解?优缺点?应用场景?
说说 Node.js 有哪些全局对象?
说说对 Node 中的 process 的理解?有哪些常用方法?
说说对 Node 中的 fs模块的理解? 有哪些常用方法
说说对 Node 中的 Buffer 的理解?应用场景?
说说对 Node 中的 Stream 的理解?应用场景?
说说Node中的EventEmitter? 如何实现一个EventEmitter?
说说对 Node.js 中的事件循环机制理解?
说说 Node 文件查找的优先级以及 Require 方法的文件查找策略?
说说对中间件概念的理解,如何封装 node 中间件?
如何实现jwt鉴权机制?说说你的思路
如何实现文件上传?说说你的思路
如果让你来设计一个分页功能, 你会怎么设计? 前后端如何交互?
Node性能如何进行监控以及优化?
项目
1. 项目中有封装过axios吗?主要是封装哪些方面
有的,主要就是随着项目规模的增大,为了方便管理和维护我们的代码,提高代码质量,在项目中都会对axios进行一个二次封装
在封装的同时需要和后端进行协商好,请求参数,状态码和请求的超时时间
主要有以下的几个方面
设置接口请求前缀,利用node环境变量来判断,区分开发,测试,生产的不同环境,
在我们本地调试的时候,如果后端没有开启cors跨域,我们就需要在vue配置文件中进行配置devServer代理转发从而实现跨域请求
请求头:在请求头里面,有的一些业务必须要携带token或者是其他的参数才可以请求,就需要对请求的配置对象在请求数据时携带上token,这样就不用每次请求数据时,还要去手动加上token
状态码:根据接口返回的不同status , 来执行不同的业务,这块需要和后端约定好
请求拦截器:依据请求头的请求设定,来决定哪些请求是可以访问的
响应拦截器:这块就是根据后端返回的状态码执行不同的业务
封装请求方法,先把axios实例引入进来,在把不同的请求方法,用一个函数保存起来,最后对外暴露出去,然后在需要使用该请求方法的页面导入,直接调用即可
可以把所有的有相同业务逻辑的请求方法写在一个api文件夹里面,就比如说,要做权限的业务,就可以把所有的请求方法放在一个permission.js的文件里面,做薪资管理的就可以把所有的请求方法放在一个salary.js的文件里面,方便后期的统一管理和维护
2. vue项目中跨域问题的解决
跨域本质是浏览器基于同源策略的一种安全手段
同源策略(Sameoriginpolicy),是一种约定,它是浏览器最核心也最基本的安全功能
所谓同源(即指在同一个域)具有以下三个相同点
- 协议相同(protocol)
- 主机相同(host)
- 端口相同(port)
反之非同源请求,也就是协议、端口、主机其中一项不相同的时候,这时候就会产生跨域
一定要注意跨域是浏览器的限制,你用抓包工具抓取接口数据,是可以看到接口已经把数据返回回来了,只是浏览器的限制,你获取不到数据。用postman请求接口能够请求到数据。这些再次印证了跨域是浏览器的限制。
二、如何解决
解决跨域的方法有很多,下面列举了三种:
- JSONP
- CORS
- Proxy
而在vue项目中,我们主要针对CORS或Proxy这两种方案进行展开
CORS
CORS (Cross-Origin Resource Sharing,跨域资源共享)是一个系统,它由一系列传输的HTTP头组成,这些HTTP头决定浏览器是否阻止前端 JavaScript 代码获取跨域请求的响应
CORS 实现起来非常方便,只需要增加一些 HTTP 头,让服务器能声明允许的访问来源
只要后端实现了 CORS,就实现了跨域
Proxy
代理(Proxy)也称网络代理,是一种特殊的网络服务,允许一个(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。一些网关、路由器等网络设备具备网络代理功能。一般认为代理服务有利于保障网络终端的隐私或安全,防止攻击
方案一
如果是通过vue-cli脚手架工具搭建项目,我们可以通过webpack为我们起一个本地服务器作为请求的代理对象
通过该服务器转发请求至目标服务器,得到结果再转发给前端,但是最终发布上线时如果web应用和接口服务器不在一起仍会跨域
在vue.config.js文件,新增以下代码
1 | amodule.exports = { |
通过axios发送请求中,配置请求的根路径
1 | axios.defaults.baseURL = '/api' |
方案二
此外,还可通过服务端实现代理请求转发
以express框架为例
1 | var express = require('express'); |
方案三
通过配置nginx实现代理
1 | server { |
3. 本地开发完后部署到服务器后404是什么原因
当我们进入到子路由时刷新页面,web容器没有相对应的页面此时会出现404
所以我们只需要配置将任意页面都重定向到 index.html,把路由交由前端处理
对nginx配置文件.conf修改,添加try_files $uri $uri/ /index.html;
1 | server { |
修改完配置文件后记得配置的更新
1 | nginx -s reload |
这么做以后,你的服务器就不再返回 404 错误页面,因为对于所有路径都会返回 index.html 文件






